Optimizer:从 SGD 到 AdamW
Optimizer:从 SGD 到 AdamW
训练神经网络就是在找一个最低点。你站在 loss 曲面的某个位置,每步沿着梯度方向往下走一点,希望最后走到谷底。
SGD 做的就是这件事:
1 | for x, y in dataloader: |
听起来简单。但真正跑起来,你会发现 loss 降着降着不动了——不是到了最低点,梯度还不是零,参数也还在更新,但 loss 就是不降。
问题出在哪?梯度告诉你的是"当前脚下最陡的下坡方向"。但如果这座山的形状是一个又窄又长的峡谷呢?最陡的方向指向峡谷的侧壁,而不是谷底。你每一步都往侧壁走,走到对面再弹回来——来来回回,沿谷底的有效位移极小。
这就是 SGD 的第一个问题:梯度方向和真正该去的方向之间有夹角。
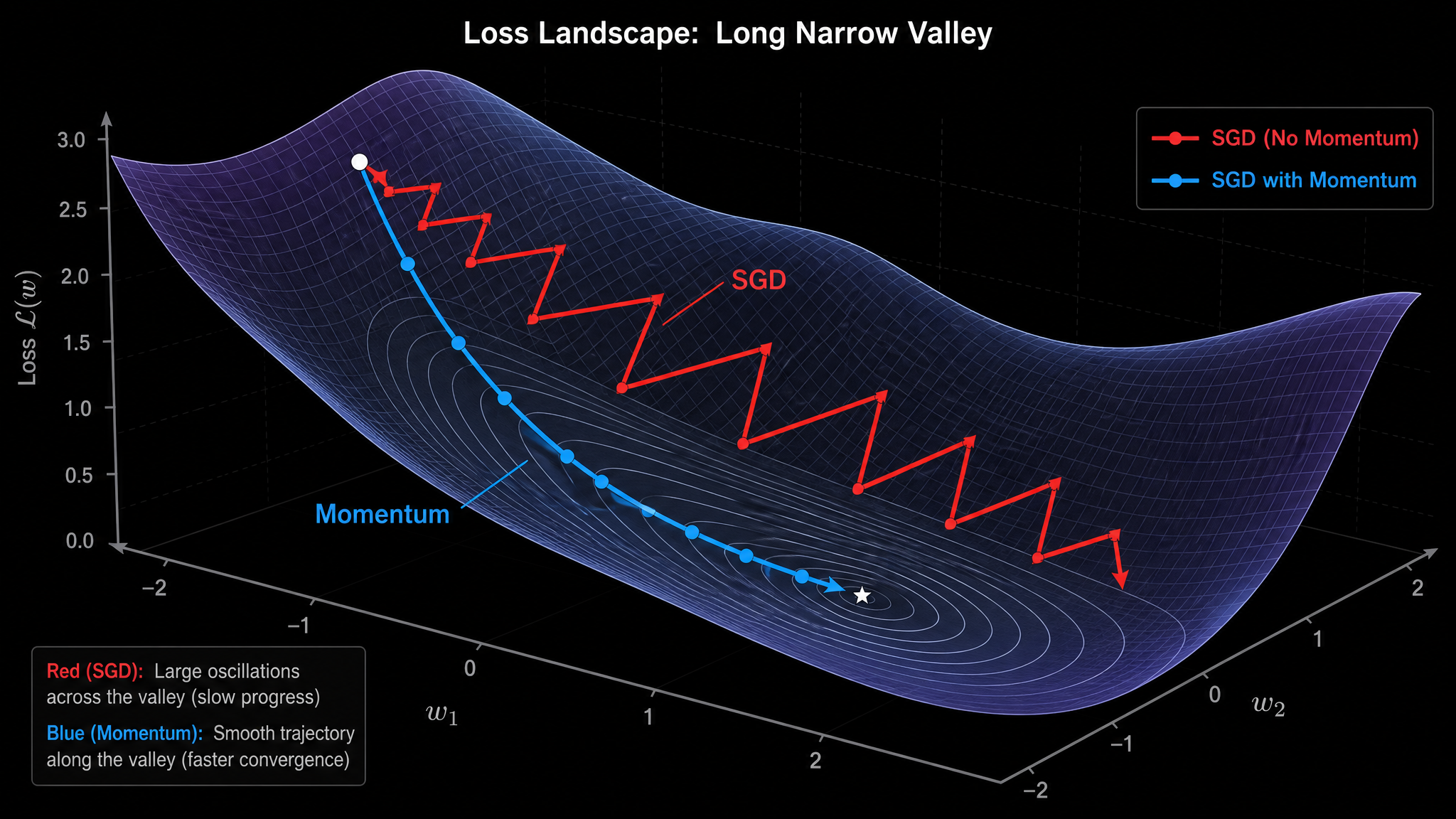
一、Momentum:让方向靠谱一点
Momentum 做的事可以用骑自行车来理解:你不可能每踩一脚就停下来重新判断方向,你会保持一个速度,根据当前路况微调。
效果是什么?如果梯度在某个方向上反复正负交替(比如峡谷两侧来回震荡),EMA 后它们互相抵消,
graph TD
G["当前梯度 g_t"] --> ACC["v_t = 0.9·v_{t-1} + g_t"]
V["上一步速度 v_{t-1}"] -->|"×0.9"| ACC
ACC --> BUF["存到 state"]
BUF --> UPDATE["θ = θ - lr·v_t"]
代码上,Momentum 只比 SGD 多存一个跟参数同 shape 的 tensor:
1 | # torch.optim.SGD(params, lr=0.01, momentum=0.9) |
到这一步,方向的问题大致解决了。但还有另一个问题:所有参数共用一个学习率。
想一下:一个 transformer 里,embedding 层的某一行可能在整个 batch 里只被一个 token 激活,梯度的量级很小。而最后一层 linear 的每一列都被 batch 里所有 token 用到,梯度量级大得多。给它们同一个学习率,embedding 层基本原地踏步。
这就是第二个问题:不同参数的梯度尺度不一样,应该给不同的学习率。
二、AdaGrad 和 RMSProp:给每个参数自己的步长
AdaGrad 的思路直截了当——给每个参数记一笔账:过去这个参数的梯度有多大。然后用这笔账反过来调它的学习率。
1 | # torch.optim.Adagrad |
但这里藏着一个 bug。
RMSProp 改了这一行:不累加,改用指数移动平均。
旧的平方值随时间衰减——100 步前的
graph LR
subgraph AdaGrad
A1["g²"] -->|"累加"| A2["G 单调增大"]
A2 --> A3["lr → 0"]
end
subgraph RMSProp
R1["g²"] -->|"EMA 旧值衰减"| R2["E[g²] 有界"]
R2 --> R3["lr 保持稳定"]
end
代码层面,AdaGrad 和 RMSProp 的差异就是一行:
1 | # AdaGrad: |
现在有两条线了。Momentum 帮所有参数把方向修直。RMSProp 给每个参数分配了合适的学习率。但这俩是分开用的——你只能选一个。
三、Adam:把两条线合到一起
Adam 把 Momentum 和 RMSProp 并到一个更新规则里:
比 Momentum + RMSProp 多了一步:偏差修正。
打个比方:你第一次估一个城市的人口,只采访了 10 个人。你当然不会直接拿 10 个人的平均值当结论——你会心里把它"放大",因为样本太少了。Adam 的偏差修正就是在做这件事:
第一步:
1 | # torch.optim.Adam 内部,每个参数维护: |
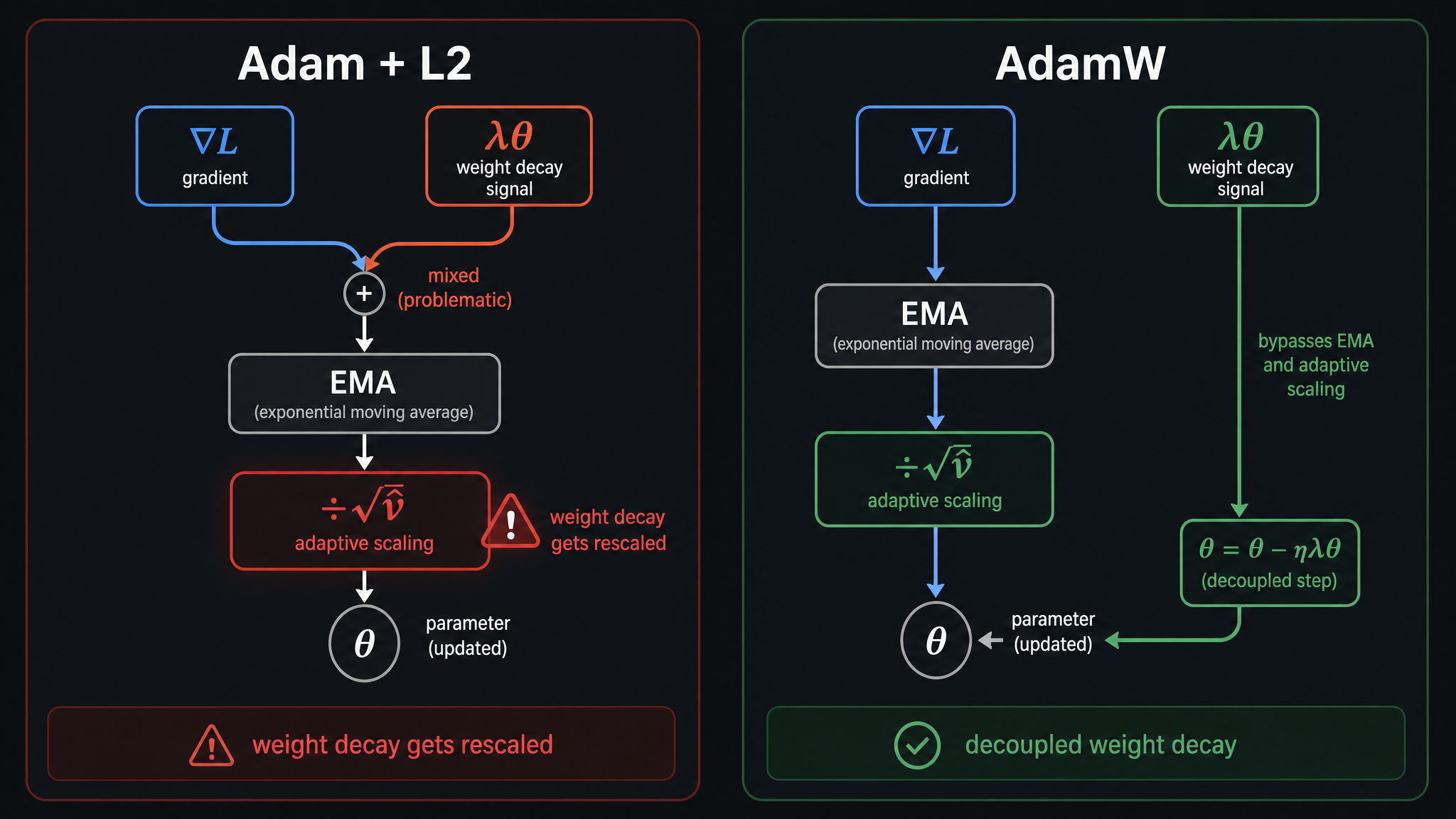
四、AdamW:修一个藏了十年的 bug
训练时经常会加 L2 正则化——在 loss 里加一项让权重趋向 0,防止过拟合。
SGD 里,L2 正则化等价于 weight decay:loss 上加
Adam 里不等价。因为 Adam 会把 L2 正则化的梯度也送进 EMA,还被
拿一个具体例子说:两个参数,一个是高频特征对应的权重(梯度方差大,
- 高频的那个:
大 → weight decay 被除一个大的分母 → 几乎没衰减 - 低频的那个:
小 → weight decay 被除一个小的分母 → 衰减过头
weight decay 的强度变得跟参数的"使用频率"挂钩了。这没有道理——一个参数用得频繁,不代表它不应该被正则化。
AdamW 的修正就是把 weight decay 从自适应机制里拆出来,直接作用在权重上:
最后那项
1 | # Adam 里 weight_decay 的路径: |
graph TD
subgraph "Adam + L2"
G1["∇L"] --> M1["grad += λθ"]
W1["θ"] --> M1
M1 --> S1["过 EMA + 被 √v̂ 缩放"]
S1 --> U1["θ 更新"]
end
subgraph "AdamW"
G2["∇L"] --> S2["过 EMA + 被 √v̂ 缩放"]
S2 --> U2["θ 更新"]
U2 --> WD["θ -= η·λ·θ (直接减)"]
end
2017 年 Loshchilov 和 Hutter 在 CIFAR-10 上做了对比:同样的 weight_decay=0.01,AdamW 比 Adam + L2 的准确率高了 1~2 个百分点。就一行代码的差别。
回过头看整条线。SGD 的方向不准——Momentum 用 EMA 把震荡抵消掉。多个参数共享一个学习率不公平——AdaGrad 给每个参数单独立账,RMSProp 修了账本只增不减的问题。两条线被 Adam 合并——最后 AdamW 把 weight decay 从自适应机制里拆出来,不再让正则化强度被
每次改动都不大。多存一个 buffer。把累加改成 EMA。把一行 grad.add_ 换成 p.mul_。但每一步补的都是训练时真实遇到的坑。