LLM 推理显存估算
一个 Llama 2 7B 模型,FP16 权重 13GB。把它装进 A100 40GB,看上去绰绰有余。batch size 拉到 8,上下文设 4096,跑两步 OOM 了。13GB 的模型在 40GB 的卡上怎么会爆?
原因是显存的主体不止权重。KV Cache 随请求数和上下文长度线性增长,注意力中间结果随序列长度平方膨胀,框架的 workspace、通信 buffer 还要再吃一块。三块加起来,部署前不算清楚,运维线上就要在 dashboard 里看 OOM 告警。
这篇文章回答一个具体问题:给定模型、上下文长度和并发请求数,一张卡到底会占多少显存。
一、权重的显存
最直觉的部分。模型的参数量
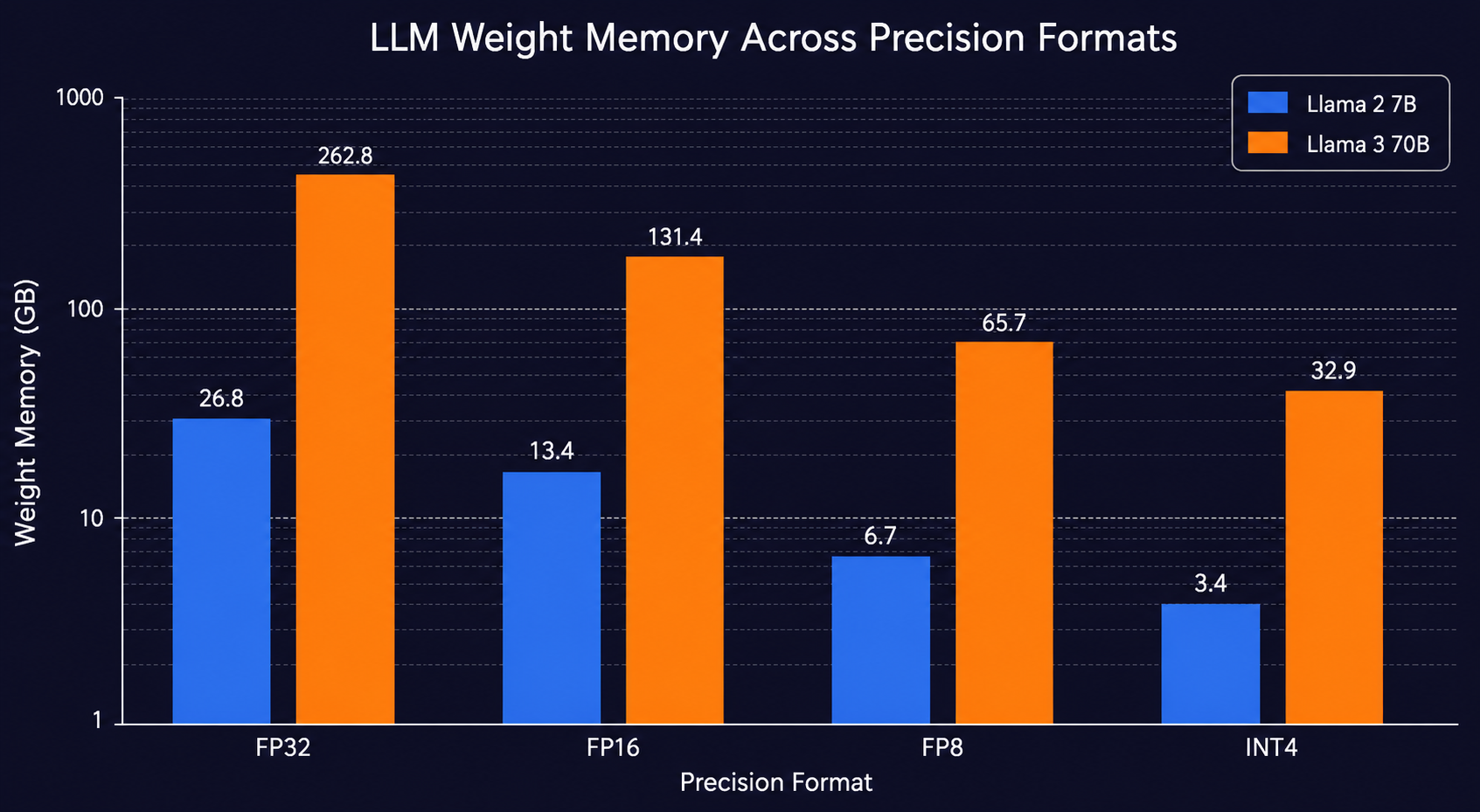
Llama 2 7B 标称 7B,实际参数量约 6.7B(含 embedding 与每一层的 attention/FFN 矩阵,typical 配置下 HF safetensors 实测 13.0GB 左右)。把它用不同精度加载:
| 精度 | bytes/param | Llama 2 7B | Llama 3 70B |
|---|---|---|---|
| FP32 | 4 | 26.8 GB | 262.8 GB |
| FP16 / BF16 | 2 | 13.4 GB | 131.4 GB |
| FP8 | 1 | 6.7 GB | 65.7 GB |
| INT4 | 0.5 | 3.4 GB | 32.9 GB |
1 | # 权重的显存本质就是参数量 × 字节宽度 |
权重的结构里,embedding 与 lm_head 是两个候选大头。Llama 2 7B 采用 embedding tying(输入 embedding 和输出 lm_head 共享权重),词表 32000 × 4096 ≈ 131M 参数只算一次,占总参数 2%;Llama 3 70B 取消 tying,且词表扩到 128256,embedding + lm_head 各占约 1.05B 参数,合计 2.1B,占 70B 总量的 3%。占比都不高——推理显存里真正的大头来自随请求线性膨胀的运行时部分,下面这一项就是。
KV Cache 概念本身(为什么要缓存、命中前后的计算量差异)在上一篇已经讲过,这里不再展开。聚焦到显存视角:KV Cache 是常驻权重之外、与请求规模直接挂钩的占用。
二、KV Cache 的显存
每生成一个 token,模型要在每一层保留这个 token 的 Key 和 Value 向量,后续 token 才能复用——这些向量在显存里堆起来就是 KV Cache。它随上下文长度和 batch size 线性增长,是推理显存里最容易失控的一项。
正确的公式对 GQA/MHA 都成立:
其中
这里特别要注意一个常见错误。网上不少估算文章直接拿
这个形式只在 MHA 下成立。换成 GQA 模型它会把 KV Cache 高估
1 | llama3_layers, hidden, n_head, n_kv, d_head = 80, 8192, 64, 8, 128 |
按正确公式逐项算单 token 的 KV Cache:
| 模型 | 精度 | 单 token KV Cache |
|---|---|---|
| Llama 2 7B(MHA) | FP16 | 0.50 MB |
| Llama 2 7B(MHA) | INT8 | 0.25 MB |
| Llama 3 70B(GQA) | FP16 | 0.31 MB |
| Llama 3 70B(GQA) | FP8 / INT8 | 0.16 MB |
Llama 3 70B 的 GQA 把单 token KV Cache 压到 Llama 2 7B 的六成左右,正是 GQA 在显存侧的核心收益——架构端就把 KV 的乘子做小了,下游一切请求数和上下文长度的乘积都跟着下降。
graph LR
A["2<br/>K + V"] -->|乘| B["n_layer<br/>层数"]
B -->|乘| C["n_kv × d_head<br/>KV 头维度"]
C -->|乘| D["seq × batch<br/>请求规模"]
D -->|乘| E["bytes<br/>精度"]
E --> F["KV Cache 总显存"]
style A fill:#fff8e1,stroke:#ff9800,color:#333
style B fill:#f0f4ff,stroke:#5b8def,color:#333
style C fill:#f0f4ff,stroke:#5b8def,color:#333
style D fill:#fce4ec,stroke:#ef5350,color:#333
style E fill:#f5f5f5,stroke:#9e9e9e,color:#333
style F fill:#e8f5e9,stroke:#4caf50,color:#333
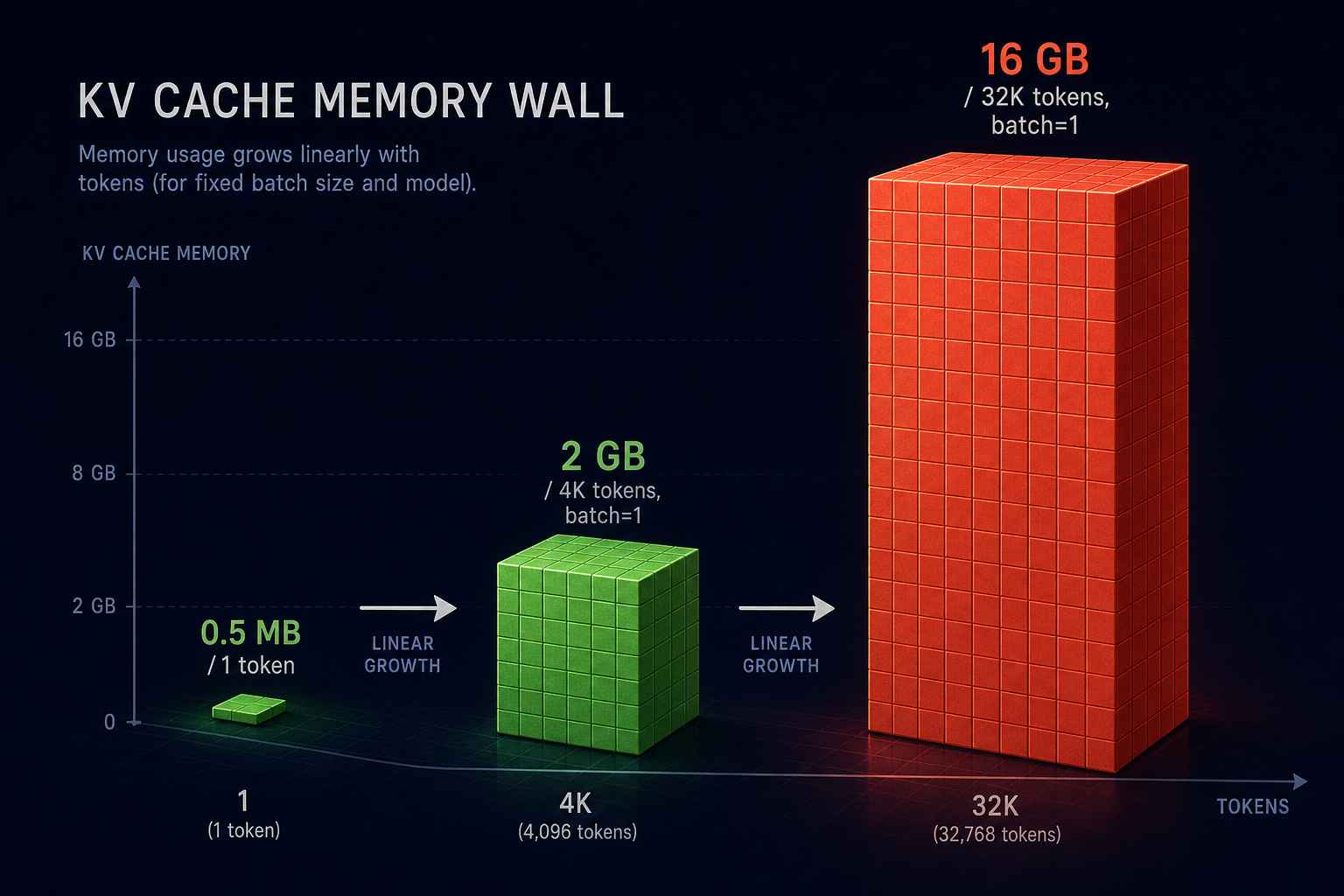
单 token 是 0.5MB 看着很小,乘上序列长度和 batch 立刻放大几个数量级:
1 | def kv_total(seq, batch, b=2): |
batch 8、上下文 4K 的多轮客服场景,单个服务的 KV Cache 就吃掉 16GB;batch 1 单把上下文拉到 32K,文档摘要这种长上下文场景也是 16GB。这就是所谓的显存墙:上下文变长 8 倍,KV Cache 也变长 8 倍,几乎不存在"反正模型才 13GB,留 27GB 给运行时怎么也够"这种话——只要业务上需要长上下文或多并发,这块就会撞上来。
到这里常驻权重和运行时 KV Cache 两项抓到位了。但每跑一层 Transformer,中间张量也要在显存里分配空间,这一块同样要算。
三、激活值的显存
激活值是前向传播里每一层中间计算的张量:attention 的 projection 结果、softmax 之前的 score 矩阵、FFN 中间层等等。它们在算完一层后理论上能释放,但峰值会卡住显存。
其中最敏感的是 attention score 矩阵。每一层、每个 head、每个样本,都要存一个
这是随序列长度平方增长的项——seq 翻一倍,这一项涨 4 倍。代入具体场景:
1 | def attn_peak(n_head, seq, batch, b=2): |
Llama 2 7B 在 batch 8、上下文 4K 时,光 attention score 峰值就要 8GB;把上下文推到 32K,单条请求就 64GB——比模型的全部权重还大 5 倍。回到开篇 OOM 的场景,把权重 13GB、KV Cache 16GB、attention 峰值 8GB 加起来已经 37GB,A100 40GB 撑在边缘,加上 PyTorch workspace 与框架临时 buffer,OOM 几乎是必然结果。
朴素 attention 这个
graph TB
subgraph 朴素Attention
A1["QK转置计算"] -->|seq平方矩阵| B1["score矩阵<br/>物化到HBM"]
B1 -->|softmax| C1["attn权重<br/>seq×seq"]
C1 -->|乘V| D1["输出"]
end
subgraph FlashAttention
A2["QK分块计算"] -->|SRAM内| B2["score分块<br/>不物化到HBM"]
B2 -->|分块softmax| C2["attn权重<br/>即时用完"]
C2 -->|乘V分块| D2["输出"]
end
style A1 fill:#fff8e1,stroke:#ff9800,color:#333
style B1 fill:#fce4ec,stroke:#ef5350,color:#333
style C1 fill:#fce4ec,stroke:#ef5350,color:#333
style D1 fill:#e8f5e9,stroke:#4caf50,color:#333
style A2 fill:#fff8e1,stroke:#ff9800,color:#333
style B2 fill:#f0f4ff,stroke:#5b8def,color:#333
style C2 fill:#f0f4ff,stroke:#5b8def,color:#333
style D2 fill:#e8f5e9,stroke:#4caf50,color:#333
除了 attention score,其它激活(Q/K/V 投影、FFN 中间层、RoPE、RMSNorm 输出)随
到这里常驻权重、KV Cache、激活峰值三块都收入公式了。剩下的问题是——上面所有数字都还有一张牌没翻:精度和切分。
四、量化与张量并行
工程上很少让一个 7B 模型以 FP16 在单卡上裸跑——要么压精度换显存,要么多卡摊销。这两件事都是直接乘上文公式里的某个因子。
量化的乘法效应
权重显存公式
把 Llama 3 70B 用不同精度组合跑(bs1 / ctx32K):
| 方案 | 权重 | KV Cache | 总计 |
|---|---|---|---|
| FP16 权重 + FP16 KV | 131 GB | 10.0 GB | 141 GB |
| INT8 权重 + INT8 KV | 65.7 GB | 5.0 GB | 70.7 GB |
| INT4 权重 + INT8 KV | 32.9 GB | 5.0 GB | 37.9 GB |
第三行 INT4 权重 + INT8 KV(GPTQ/AWQ 量化配 FP8 KV 是常见组合)能把 70B 模型压进单张 80GB 卡里跑 32K 上下文。精度损失在现代量化方案下通常小于 1 个点,对生产可用。
张量并行的切分
70B 模型 FP16 权重 131GB,单卡无论如何装不下,必须切到多卡。张量并行(TP)按 head 维度把 attention 矩阵切到各卡,权重和激活都按
| 配置 | 每卡权重 | 每卡 KV | 每卡可用 KV 池(80GB 卡) |
|---|---|---|---|
| 单卡 | 131 GB | 装不下 | — |
| TP=2 | 65.7 GB | 5.0 GB/卡 (bs1) | 不到 10 GB |
| TP=4 | 32.9 GB | 2.5 GB/卡 | 47 GB |
| TP=8 | 16.4 GB | 1.25 GB/卡 | 62 GB |
TP 对权重的切分是干净线性;对 KV Cache 的切分稍有出入——KV 分组能均匀切到各卡,但 batch 维度共享的部分(在做 PagedAttention 的 block 池时)框架实现有差异。粗算按
TP 还需要一份 all-reduce 通信的临时 buffer,大小是

至此,公式里每一个变量都对应到工程上一个真实字段。最后把它们组合起来。
端到端公式
把全文的项汇总成一个可直接代入的公式:
常见部署目标的速查表(A100 80GB / H100 80GB):
| 模型 | 精度 | 上下文 | batch | 单卡显存需求 | 推荐配置 |
|---|---|---|---|---|---|
| Llama 2 7B | FP16 | 4K | 8 | 约 37 GB(朴素 attn)/ 29 GB(Flash) | 单卡 80GB |
| Llama 2 7B | INT4 | 4K | 8 | 约 27 GB | 单卡 40GB |
| Llama 3 70B | FP16 | 32K | 1 | 141 GB | TP=2 × 80GB |
| Llama 3 70B | INT4+INT8 KV | 32K | 1 | 38 GB | 单卡 80GB |
这张表里每一行都是把上面三项加起来再贴一点框架开销得来的。把部署场景的模型/精度/上下文/batch 代入公式,再算上 10%—15% 的裕量,就是上线前应该摆在容量规划文档里的数字。
公式给的是上限。工程上同一份模型、同一份请求,实际显存峰值仍然会受推理框架的实现影响——PagedAttention 把 KV Cache 拆成 block 池做碎片化管理,vLLM 在连续批处理里按需分配 KV 块,FlashAttention 把 attention score 峰值从显存拽回 SRAM。这些都是把上面公式里的某一项进一步压低。下一篇就讲其中最关键的一项:FlashAttention 是怎么把