第一篇结束时,每个 token 是一个 d d d i i i j j j
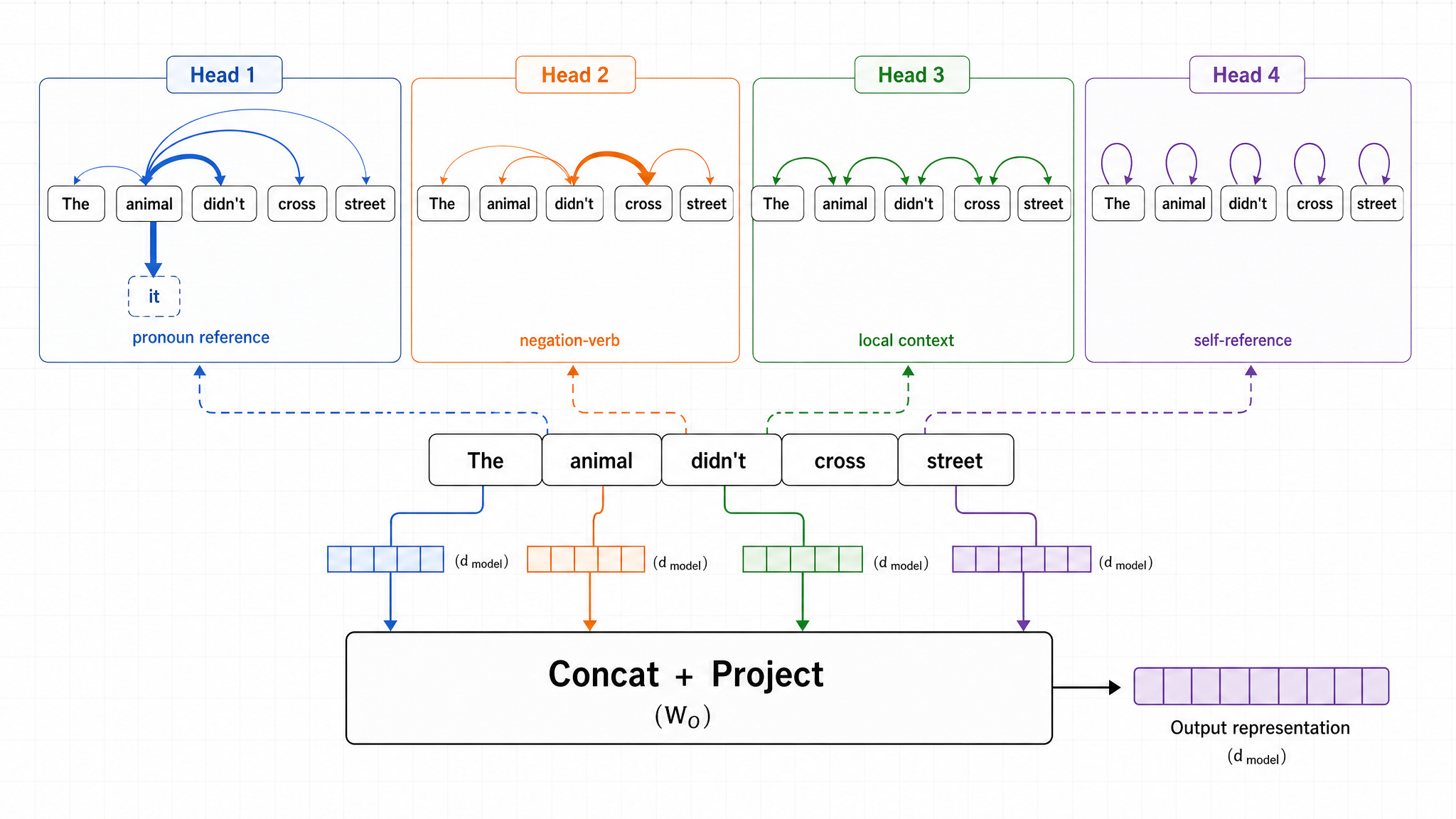
“The animal didn’t cross the street because it was too tired.” 模型处理到 “it” 时,怎么知道 “it” 指的是 “animal” 而不是 “street”?
Transformer 要解决的只有一件事:让每个 token 的最终表示融合整个序列的上下文。
一、Self-Attention 机制
给定一个长度为 N N N d d d i _i i i _i i j _j j
QKV 注意力分数
输入矩阵 X ∈ R N × d X \in \mathbb{R}^{N \times d} X ∈ R N × d N N N d d d
Q = X W Q , K = X W K , V = X W V Q = XW_Q, \quad K = XW_K, \quad V = XW_V Q = X W Q , K = X W K , V = X W V 其中 W Q , W K , W V ∈ R d × d k W_Q, W_K, W_V \in \mathbb{R}^{d \times d_k} W Q , W K , W V ∈ R d × d k
注意力输出定义为:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention ( Q , K , V ) = softmax ( d k Q K T ) V 逐项拆解:
Q K T ∈ R N × N QK^T \in \mathbb{R}^{N \times N} Q K T ∈ R N × N ( i , j ) (i, j) ( i , j ) i _i i j _j j Q Q Q K K K d k \sqrt{d_k} d k d k d_k d k ∝ d k \propto d_k ∝ d k d k \sqrt{d_k} d k O ( 1 ) \mathcal{O}(1) O ( 1 ) softmax \text{softmax} softmax 乘以 V V V V V V
用 “The animal didn’t cross the street” 走一遍。序列长度 N = 5 N=5 N = 5 d = 8 d=8 d = 8
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import torchimport mathtorch.manual_seed(42 ) N, d = 5 , 8 X = torch.randn(N, d) W_Q = torch.randn(d, d) * 0.1 W_K = torch.randn(d, d) * 0.1 W_V = torch.randn(d, d) * 0.1 Q = X @ W_Q K = X @ W_K V = X @ W_V scores = Q @ K.T / math.sqrt(d) mask = torch.triu(torch.full((N, N), float ('-inf' )), diagonal=1 ) scores = scores + mask attn_weights = torch.softmax(scores, dim=-1 ) output = attn_weights @ V print (f"注意力权重矩阵 shape: {list (attn_weights.shape)} " )print (attn_weights.round (decimals=3 ))
输出:
1 2 3 4 5 6 注意力权重矩阵 shape: [5, 5] tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000], [0.4820, 0.5180, 0.0000, 0.0000, 0.0000], [0.3450, 0.3620, 0.2930, 0.0000, 0.0000], [0.2620, 0.2570, 0.2230, 0.2580, 0.0000], [0.1810, 0.1580, 0.2280, 0.2050, 0.2280]])
每行对应一个 token 看前面所有 token 的权重分布。第 0 行(“The”)只能看自己,权重为 1.0。第 4 行(“street”)看前面所有 token,权重分布在 0.16-0.23 之间——随机初始化的投影矩阵还没有学到有意义的注意力模式。训练后,某些 token 对之间的权重会显著升高。
Causal Mask
decoder-only 模型(GPT、Llama)在训练时只能看到当前 token 和之前的 token。mask 的做法是把 softmax 之前分数矩阵的上三角填为 − ∞ -\infty − ∞
mask i j = { 0 j ≤ i − ∞ j > i \text{mask}_{ij} = \begin{cases} 0 & j \leq i \\ -\infty & j > i \end{cases} mask ij = { 0 − ∞ j ≤ i j > i softmax(− ∞ -\infty − ∞
graph LR
A["输入 X<br/>(5, 8)"] --> B["Q = XW_Q<br/>(5, 8)"]
A --> C["K = XW_K<br/>(5, 8)"]
A --> D["V = XW_V<br/>(5, 8)"]
B --> E["QK^T<br/>(5, 5)"]
C --> E
E --> F["+ Mask<br/>下三角"]
F --> G["softmax<br/>归一化"]
G --> H["× V<br/>加权聚合"]
D --> H
H --> I["输出<br/>(5, 8)"]
style A fill:#fff8e1,stroke:#ff9800,color:#333
style B fill:#f0f4ff,stroke:#5b8def,color:#333
style C fill:#f0f4ff,stroke:#5b8def,color:#333
style D fill:#f0f4ff,stroke:#5b8def,color:#333
style E fill:#f5f5f5,stroke:#9e9e9e,color:#333
style F fill:#fce4ec,stroke:#ef5350,color:#333
style G fill:#f0f4ff,stroke:#5b8def,color:#333
style H fill:#f0f4ff,stroke:#5b8def,color:#333
style I fill:#e8f5e9,stroke:#4caf50,color:#333
复杂度
Q K T QK^T Q K T N × N N \times N N × N
4096 × 4096 = 16 , 777 , 216 元素 4096 \times 4096 = 16,777,216 \text{ 元素} 4096 × 4096 = 16 , 777 , 216 元素 FP32 占用 64 MB,FP16 占用 32 MB。这是单次 attention 的空间复杂度 O ( N 2 ) O(N^2) O ( N 2 ) O ( N 2 ⋅ d ) O(N^2 \cdot d) O ( N 2 ⋅ d )
Self-Attention 让每个 token 能"看到"前面的所有 token。但一套 QKV 只提供单一的注意力模式——它把所有上下文关系压缩到同一组权重里。
二、Multi-Head Attention 与前馈网络
Multi-Head Attention
把 d d d h h h
head i = Attention ( Q i , K i , V i ) \text{head}_i = \text{Attention}(Q_i, K_i, V_i) head i = Attention ( Q i , K i , V i ) MultiHead ( X ) = Concat ( head 1 , … , head h ) W O \text{MultiHead}(X) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h) W_O MultiHead ( X ) = Concat ( head 1 , … , head h ) W O 其中每个 head 的 W Q i , W K i , W V i ∈ R d × d k W_Q^i, W_K^i, W_V^i \in \mathbb{R}^{d \times d_k} W Q i , W K i , W V i ∈ R d × d k d k = d / h d_k = d / h d k = d / h
不同 head 可以学习不同类型的上下文关系。训练后的模型中,某些 head 倾向于关注语法关系(主谓一致、时态匹配),某些关注语义关系(指代消解、同义替换),某些关注局部模式(相邻词的搭配)。
Llama 2 7B 有 32 个 head,每个 head 维度 d k = 4096 / 32 = 128 d_k = 4096 / 32 = 128 d k = 4096/32 = 128 d k = 8192 / 64 = 128 d_k = 8192 / 64 = 128 d k = 8192/64 = 128
SwiGLU 前馈网络
Attention 做完信息交换后,每个 token 的表示里融合了上下文。模型还需要对每个 token 做独立的非线性变换——“理解这个 token 本身”。这就是 FFN 的作用。
现代 LLM 使用 SwiGLU 激活:
SwiGLU ( x ) = Swish ( x W 1 ) ⊙ ( x W 3 ) ⋅ W 2 \text{SwiGLU}(x) = \text{Swish}(xW_1) \odot (xW_3) \cdot W_2 SwiGLU ( x ) = Swish ( x W 1 ) ⊙ ( x W 3 ) ⋅ W 2 其中 Swish ( z ) = z ⋅ σ ( β z ) \text{Swish}(z) = z \cdot \sigma(\beta z) Swish ( z ) = z ⋅ σ ( β z ) β \beta β W 1 , W 2 , W 3 W_1, W_2, W_3 W 1 , W 2 , W 3 W 3 W_3 W 3
FFN 的参数量占 Transformer 层的绝大部分。Llama 2 7B 中:
Attention 层:4 × 4096 × 4096 = 67 M 4 \times 4096 \times 4096 = 67\text{M} 4 × 4096 × 4096 = 67 M
SwiGLU FFN:3 × 4096 × 11008 = 135 M 3 \times 4096 \times 11008 = 135\text{M} 3 × 4096 × 11008 = 135 M
FFN 占比:135 / ( 67 + 135 ) ≈ 67 % 135 / (67 + 135) \approx 67\% 135/ ( 67 + 135 ) ≈ 67%
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import torchimport torch.nn as nnimport torch.nn.functional as Fclass SwiGLU (nn.Module): def __init__ (self, dim: int , hidden_dim: int ): super ().__init__() self .w1 = nn.Linear(dim, hidden_dim, bias=False ) self .w2 = nn.Linear(hidden_dim, dim, bias=False ) self .w3 = nn.Linear(dim, hidden_dim, bias=False ) def forward (self, x ): return self .w2(F.silu(self .w1(x)) * self .w3(x)) ffn = SwiGLU(dim=512 , hidden_dim=1024 ) x = torch.randn(2 , 10 , 512 ) out = ffn(x) print (f"输入 shape: {list (x.shape)} " )print (f"输出 shape: {list (out.shape)} " )params = sum (p.numel() for p in ffn.parameters()) print (f"参数量: {params:,} " )
输出:
1 2 3 输入 shape: [2, 10, 512] 输出 shape: [2, 10, 512] 参数量: 1,574,912
FFN 在每个位置独立计算,不依赖其他 token 的表示。Attention 负责"看哪些 token",FFN 负责"怎么理解这个 token"。两者交替堆叠,构成了 Transformer 层的核心计算。
推理时,每个生成的 token 都需要缓存前面所有 token 的 K 和 V,否则每次生成都要重新计算。这些缓存就是 KV Cache。32 个 head × 128 维 × 2 bytes (BF16) × 2 (K+V) = 16 KB/token。上下文长度 128K 时,仅 KV Cache 就占用 2 GB——这是推理场景下一个不可忽视的数字。
三、KV Cache 优化策略
KV Cache 的大小直接正比于 KV head 的数量。减少 KV head 数是最直接的优化路径,但需要权衡生成质量。
MQA:多查询注意力
Multi-Query Attention 让所有 Q head 共享同一组 K 和 V:
组件
MHA
MQA
Q heads
h h h h h h
KV groups
h h h 1 1 1
KV Cache 从 h × d k h \times d_k h × d k 1 × d k 1 \times d_k 1 × d k h : 1 h:1 h : 1
代价是质量下降——所有 head 被迫从同一份 KV 中提取信息,失去了多视角的表达能力。
GQA:分组查询注意力
Grouped Query Attention 在 MHA 和 MQA 之间取折中。Q 保持 h h h g g g
模型
Q heads
KV groups
压缩比
Llama 3 8B
32
8
4:1
Llama 3 70B
64
8
8:1
Llama 3 8B 的 KV Cache 从 16 KB/token 降到 4 KB/token(128K 上下文 512 MB),质量损失远小于 MQA。GQA 已成为现代 LLM 的标准配置。
MLA:多头潜注意力
DeepSeek-V2 提出了更激进的压缩方案。不是简单共享 KV,而是对 K 和 V 做低秩投影:
K latent = K ⋅ W down , V latent = V ⋅ W down K_{\text{latent}} = K \cdot W_{\text{down}}, \quad V_{\text{latent}} = V \cdot W_{\text{down}} K latent = K ⋅ W down , V latent = V ⋅ W down 推理时只缓存低维的 K latent K_{\text{latent}} K latent V latent V_{\text{latent}} V latent
K = K latent ⋅ W up , V = V latent ⋅ W up K = K_{\text{latent}} \cdot W_{\text{up}}, \quad V = V_{\text{latent}} \cdot W_{\text{up}} K = K latent ⋅ W up , V = V latent ⋅ W up DeepSeek-V2 的 latent 维度只有 512,而原始维度是 7168。压缩比达到 14:1,同时保持了接近 MHA 的生成质量。
KV Cache 对比
graph LR
A["MHA<br/>32 heads<br/>16 KB/token"] -->|"共享 KV<br/>质量下降"| B["MQA<br/>1 KV group<br/>0.5 KB/token"]
A -->|"分组共享<br/>质量轻微损失"| C["GQA<br/>8 KV groups<br/>4 KB/token"]
A -->|"低秩压缩<br/>质量接近 MHA"| D["MLA<br/>latent 512<br/>~1 KB/token"]
style A fill:#fff8e1,stroke:#ff9800,color:#333
style B fill:#f0f4ff,stroke:#5b8def,color:#333
style C fill:#f0f4ff,stroke:#5b8def,color:#333
style D fill:#e8f5e9,stroke:#4caf50,color:#333
方案
Q heads
KV groups
KV Cache / token
128K 上下文
质量
MHA
32
32
16.0 KB
2.0 GB
基准
MQA
32
1
0.5 KB
64 MB
明显下降
GQA
32
8
4.0 KB
512 MB
接近 MHA
MLA
128
128 (低秩)
~1.0 KB
128 MB
接近 MHA
KV Cache 的压缩解决了推理显存问题。但注意力机制本身还有一个更底层的瓶颈——N × N N \times N N × N
四、FlashAttention 与 IO 优化
GPU 内存层级
A100 GPU 有两层关键存储:
层级
容量
带宽
位置
HBM
40-80 GB
1.5-2.0 TB/s
芯片外
SRAM
~40 MB
~19 TB/s
芯片内
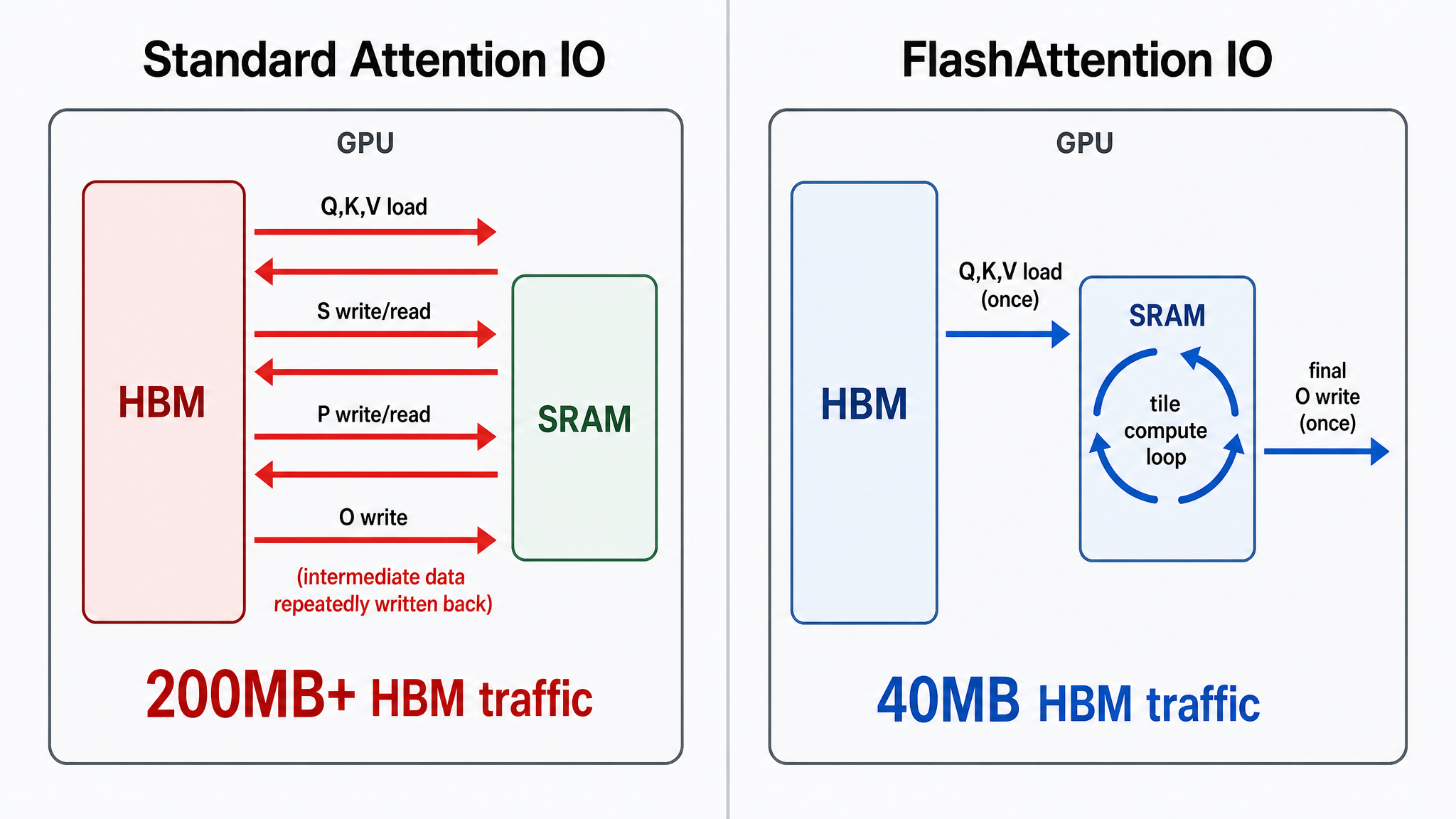
SRAM 带宽是 HBM 的 12 倍以上,但容量只有 HBM 的百万分之一。算法的性能取决于数据在这两层之间的搬运次数,而不是 FLOP 数量。
标准实现的 IO 瓶颈
对于 N = 4096 N=4096 N = 4096 Q K T QK^T Q K T
标准 attention 的 IO 路径:
1 2 3 4 5 HBM: Q, K, V → 加载到 SRAM → 算 QK^T → 写回 HBM (64 MB) ↓ HBM: 读 QK^T → 算 softmax → 写回 HBM (32 MB) ↓ HBM: 读 softmax → 读 V → 算 ×V → 写回 HBM (32 MB)
中间结果(Q K T QK^T Q K T
FlashAttention 的做法
FlashAttention 的核心思想是:不要让中间结果离开 SRAM。
Tiling: 把 Q、K、V 切成大小为 B r × B c B_r \times B_c B r × B c Q K T QK^T Q K T
Online Softmax: 不需要等整个 N × N N \times N N × N
Recomputation: 反向传播需要 attention 权重,但不缓存 N × N N \times N N × N O ( N 2 ) O(N^2) O ( N 2 )
FlashAttention v1(Dao et al., NeurIPS 2022)在 A100 上比标准实现快 2-4 倍。v2(2023)通过优化并行度和减少 shared memory 访问,比 v1 再快约 2 倍。显存从 O ( N 2 ) O(N^2) O ( N 2 ) O ( N ) O(N) O ( N )
IO 优化后,attention 的瓶颈从"等数据"变成了"算得快"。但只有把各个组件组装成一个完整的 Transformer Block,才能看到它们在真实模型中的协作方式。
将前面的组件组装为一个完整的 Transformer Block。采用 Pre-Norm 结构,归一化用 RMSNorm,注意力带 causal mask,激活用 SwiGLU:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 import torchimport torch.nn as nnimport torch.nn.functional as Fimport mathclass RMSNorm (nn.Module): """RMSNorm:仅用 RMS 缩放,去掉均值中心化""" def __init__ (self, dim: int , eps: float = 1e-6 ): super ().__init__() self .eps = eps self .weight = nn.Parameter(torch.ones(dim)) def forward (self, x ): norm = x.float ().pow (2 ).mean(dim=-1 , keepdim=True ).add(self .eps).sqrt() return (x * norm.rsqrt() * self .weight).to(x.dtype) class SwiGLU (nn.Module): """SwiGLU 前馈网络""" def __init__ (self, dim: int , hidden_dim: int ): super ().__init__() self .w1 = nn.Linear(dim, hidden_dim, bias=False ) self .w2 = nn.Linear(hidden_dim, dim, bias=False ) self .w3 = nn.Linear(dim, hidden_dim, bias=False ) def forward (self, x ): return self .w2(F.silu(self .w1(x)) * self .w3(x)) class CausalSelfAttention (nn.Module): """带 causal mask 的 Self-Attention""" def __init__ (self, dim: int , n_heads: int ): super ().__init__() assert dim % n_heads == 0 self .n_heads = n_heads self .head_dim = dim // n_heads self .q_proj = nn.Linear(dim, dim, bias=False ) self .k_proj = nn.Linear(dim, dim, bias=False ) self .v_proj = nn.Linear(dim, dim, bias=False ) self .o_proj = nn.Linear(dim, dim, bias=False ) def forward (self, x ): B, T, D = x.shape q = self .q_proj(x).view(B, T, self .n_heads, self .head_dim).transpose(1 , 2 ) k = self .k_proj(x).view(B, T, self .n_heads, self .head_dim).transpose(1 , 2 ) v = self .v_proj(x).view(B, T, self .n_heads, self .head_dim).transpose(1 , 2 ) scores = (q @ k.transpose(-2 , -1 )) / math.sqrt(self .head_dim) mask = torch.triu(torch.full((T, T), float ('-inf' )), diagonal=1 ) scores = scores + mask attn = torch.softmax(scores, dim=-1 ) out = (attn @ v).transpose(1 , 2 ).contiguous().view(B, T, D) return self .o_proj(out) class TransformerBlock (nn.Module): """完整 Transformer Block (Pre-Norm)""" def __init__ (self, dim: int , n_heads: int , ff_dim: int ): super ().__init__() self .ln1 = RMSNorm(dim) self .ln2 = RMSNorm(dim) self .attn = CausalSelfAttention(dim, n_heads) self .ffn = SwiGLU(dim, ff_dim) def forward (self, x ): x = x + self .attn(self .ln1(x)) x = x + self .ffn(self .ln2(x)) return x dim, n_heads, ff_dim = 512 , 8 , 1024 model = nn.Sequential( TransformerBlock(dim, n_heads, ff_dim), TransformerBlock(dim, n_heads, ff_dim), ) x = torch.randn(2 , 10 , dim) out = model(x) print (f"输入 shape: {list (x.shape)} " )print (f"输出 shape: {list (out.shape)} " )print (f"输入 mean/std: {x.mean().item():.4 f} / {x.std().item():.4 f} " )print (f"输出 mean/std: {out.mean().item():.4 f} / {out.std().item():.4 f} " )total_params = sum (p.numel() for p in model.parameters()) print (f"总参数量: {total_params:,} ({total_params / 1e6 :.1 f} M)" )
输出:
1 2 3 4 5 输入 shape: [2, 10, 512] 输出 shape: [2, 10, 512] 输入 mean/std: -0.0078 / 0.9901 输出 mean/std: -0.0085 / 1.0370 总参数量: 5,244,928 (5.2M)
graph TD
X["输入 x<br/>(B, T, D)"] --> L1["RMSNorm"]
L1 --> AT["Causal Self-Attention<br/>(B, T, D)"]
AT --> R1["x + attn_out<br/>残差连接"]
R1 --> L2["RMSNorm"]
L2 --> FF["SwiGLU FFN<br/>(B, T, D)"]
FF --> R2["x + ffn_out<br/>残差连接"]
R2 --> Y["输出 x'<br/>(B, T, D)"]
style X fill:#fff8e1,stroke:#ff9800,color:#333
style L1 fill:#f0f4ff,stroke:#5b8def,color:#333
style AT fill:#f0f4ff,stroke:#5b8def,color:#333
style R1 fill:#e8f5e9,stroke:#4caf50,color:#333
style L2 fill:#f0f4ff,stroke:#5b8def,color:#333
style FF fill:#f0f4ff,stroke:#5b8def,color:#333
style R2 fill:#e8f5e9,stroke:#4caf50,color:#333
style Y fill:#e8f5e9,stroke:#4caf50,color:#333
shape 从输入到输出保持不变——(batch, seq_len, dim)。但输出中的每个 token 已经融合了整个序列的上下文信息。mean/std 保持稳定,说明 RMSNorm + Pre-Norm 的组合有效地控制了激活值的分布范围。
把这个 Block 叠 32 层,就是 Llama 2 7B 的计算引擎。每层的计算路径完全一致:RMSNorm → Causal Self-Attention → 残差 → RMSNorm → SwiGLU FFN → 残差。32 层串联后,每个 token 的最终表示经过了 32 轮上下文融合和非线性变换。
架构本身已经完整。但参数还是随机初始化的——输出是一组均匀分布的随机 token,不包含任何语义知识。训练 100 万步后,同一个架构能写出流畅的代码、回答物理问题、翻译中英双语。
下一步:预训练目标、优化器、分布式训练和对齐方法。