从文本到向量:LLM 的数据管道
你在终端里输入一段 prompt,几秒后模型返回了一段流畅的回答。
但在模型"看到"你的 prompt 之前,它已经花了数月时间阅读互联网上的万亿级文本。
这些文本——HTML、PDF、代码、论坛帖子——是如何变成模型能理解的数字的?
本文是系列第一篇,回答一个问题:如何把人类语言变成模型能吃的数字?
链路分三步:清洗原始语料 → 将文本切分为 Token → 将 Token 映射为向量。每一步的输出是下一步的输入,每一步的设计决策都直接影响模型的最终能力。
一、语料工程:从互联网到训练数据集
原始数据长什么样
Common Crawl 每月抓取数十亿网页,原始数据是 HTML。随便取一条:
1 | <html><head><title>Buy cheap shoes!!!</title></head> |
广告、重复内容、样板文字混在一起。直接拿去训练,模型会把网页噪声当作语言模式来学习。
去重:MinHash + LSH
同一段文字在互联网上可能出现几千次——Wikipedia 镜像、转载文章、CMS 模板生成的页面。如果不去重,模型会在相同数据上过拟合:背下来而不是学进去。
MinHash 用哈希签名近似计算两篇文档的 Jaccard 相似度。对于文档
MinHash 的概率性质保证了签名匹配的概率恰好等于 Jaccard 相似度:
实际操作中,对每篇文档计算多个哈希函数的最小值,组成签名向量。签名相近的文档通过 LSH(Locality-Sensitive Hashing)分到同一桶中,同桶文档视为近似重复。
1 | 文档 A: "The cat sat on the mat" |
质量过滤
去重之后,还需要过滤低质量文本。两种常见方法:
Perplexity Filter: 用一个小型语言模型计算文档的困惑度:
Perplexity 过高意味着文本不自然(乱码、机器生成的垃圾),过低意味着文本过于简单或重复(“the the the…”)。保留 perplexity 在合理范围内的文档。
Classifier Filter: 训练一个二分类器,正例是 Wikipedia 和高质量书籍,负例是随机网页。用分类器的概率分数作为质量分数,保留高分文档。
数据配比与 Scaling Law
清洗后的数据来自不同来源,配比直接影响模型能力:
| 来源 | Llama 1 | Llama 3 |
|---|---|---|
| Web | 67% | ~85% |
| Code | 4.5% | ~8% |
| Books | 4.5% | — |
| 学术 | 2.5% | — |
Code 数据的比例影响模型的编程能力,学术数据影响推理能力。这不是一个有标准答案的问题——不同团队根据目标能力做不同取舍。
Chinchilla Scaling Law 给出了数据量的理论约束。给定计算预算
早期模型(GPT-3,175B 参数,300B token)参数多、数据少,处于欠训练状态。Chinchilla 证明:同等计算预算下,更小模型 + 更多数据优于更大模型 + 更少数据。Llama 1 的 7B 模型用 1T token 训练,正是这一发现的工程实践。
整个数据清洗流程可以用一张图概括:
graph LR
A["原始 HTML<br/>Common Crawl"] -->|MinHash + LSH| B["去重文档"]
B -->|Perplexity / Classifier| C["高质量文档"]
C -->|按来源配比| D["训练语料"]
D -->|统计分析| E["数据质量报告"]
style A fill:#fff8e1,stroke:#ff9800,color:#333
style B fill:#f0f4ff,stroke:#5b8def,color:#333
style C fill:#f0f4ff,stroke:#5b8def,color:#333
style D fill:#e8f5e9,stroke:#4caf50,color:#333
style E fill:#e8f5e9,stroke:#4caf50,color:#333
到这里,我们有了干净的文本语料。但文本是给人看的字符流,不是给机器看的数字序列。下一个问题:怎么把这些字符串切成模型能处理的单元?
二、Tokenization:文本的数字化
字符级、单词级、子词级
最直接的想法是按字符切分。问题在于词表太小(英文只有 ~256 个字节),序列太长。“understanding” 需要 13 个字符 token,模型需要学会拼接才能理解词义——这把简单问题复杂化了。
另一个极端是按单词切分。词表爆炸(英文 50 万+),无法处理未登录词。“tokenization” 如果不在词表中,就变成 <UNK>——模型完全丢失了这个词的信息。
子词级(Subword) 取中间路线:常见词保持完整,罕见词拆分为子词片段。“unhappiness” → [“un”, “happiness”],即使模型没见过完整词,也能从子词组合推断含义。
BPE 算法:从字节到子词
Byte-Pair Encoding(BPE)是最主流的子词切分算法。GPT 系列、Llama 系列都使用 BPE 或其变体。
合并过程:
- 初始词表:所有单个字节(256 个)
- 统计语料中所有相邻字节对的出现频率
- 合并频率最高的字节对为新 Token,加入词表
- 重复步骤 2-3,直到词表达到目标大小
用一个具体字符串走一遍:
1 | # 语料 |
完整实现只需要两个函数:
1 | def get_stats(ids): |
graph LR
S["the cat sat on the mat"] -->|"字节编码"| B["116 104 101 32 99 97 116 ..."]
B -->|"统计 pair 频率"| P["(101,32)=4次<br/>(116,104)=3次<br/>(104,101)=3次"]
P -->|"合并最高频"| M1["'e ' → token 256"]
M1 -->|"重复"| M2["'th' → token 257"]
M2 -->|"重复"| M3["'the' → token 258"]
M3 -->|"直到词表达标"| F["最终 token 序列"]
style S fill:#fff8e1,stroke:#ff9800,color:#333
style B fill:#f5f5f5,stroke:#9e9e9e,color:#333
style P fill:#f5f5f5,stroke:#9e9e9e,color:#333
style M1 fill:#fce4ec,stroke:#ef5350,color:#333
style M2 fill:#fce4ec,stroke:#ef5350,color:#333
style M3 fill:#fce4ec,stroke:#ef5350,color:#333
style F fill:#e8f5e9,stroke:#4caf50,color:#333
真实模型的 Tokenizer 长什么样
用 GPT-2 的 tokenizer 跑几个例子:
1 | import tiktoken |
“The”、“fox” 是单个 token,“antidisestablishmentarianism” 被拆成 7 个子词。Tokenization 的粒度直接决定了模型处理每个词需要多少步计算。
词表大小的工程权衡
| 词表大小 | 序列长度 | Embedding 参数量 | 效果 |
|---|---|---|---|
| 小 (8K) | 长 | 少 | 拆分多,中文/代码效率低 |
| 中 (32K) | 中 | 中 | Llama 1/2 的选择 |
| 大 (128K) | 短 | 多 | Llama 3 的选择,多语言更友好 |
Embedding 参数量 = 词表大小 × 隐藏维度。Llama 1 用 32K 词表,Embedding 占
到这里,文本被切成了 Token ID 序列——一个整数列表。但 Token ID 是离散的,ID=42 和 ID=1337 之间的数值差异没有语义含义。“cat” 和 “dog” 的 ID 之间没有天然的相似性。如何让模型知道这两个词是相关的?
三、Embedding:从离散 ID 到连续语义空间
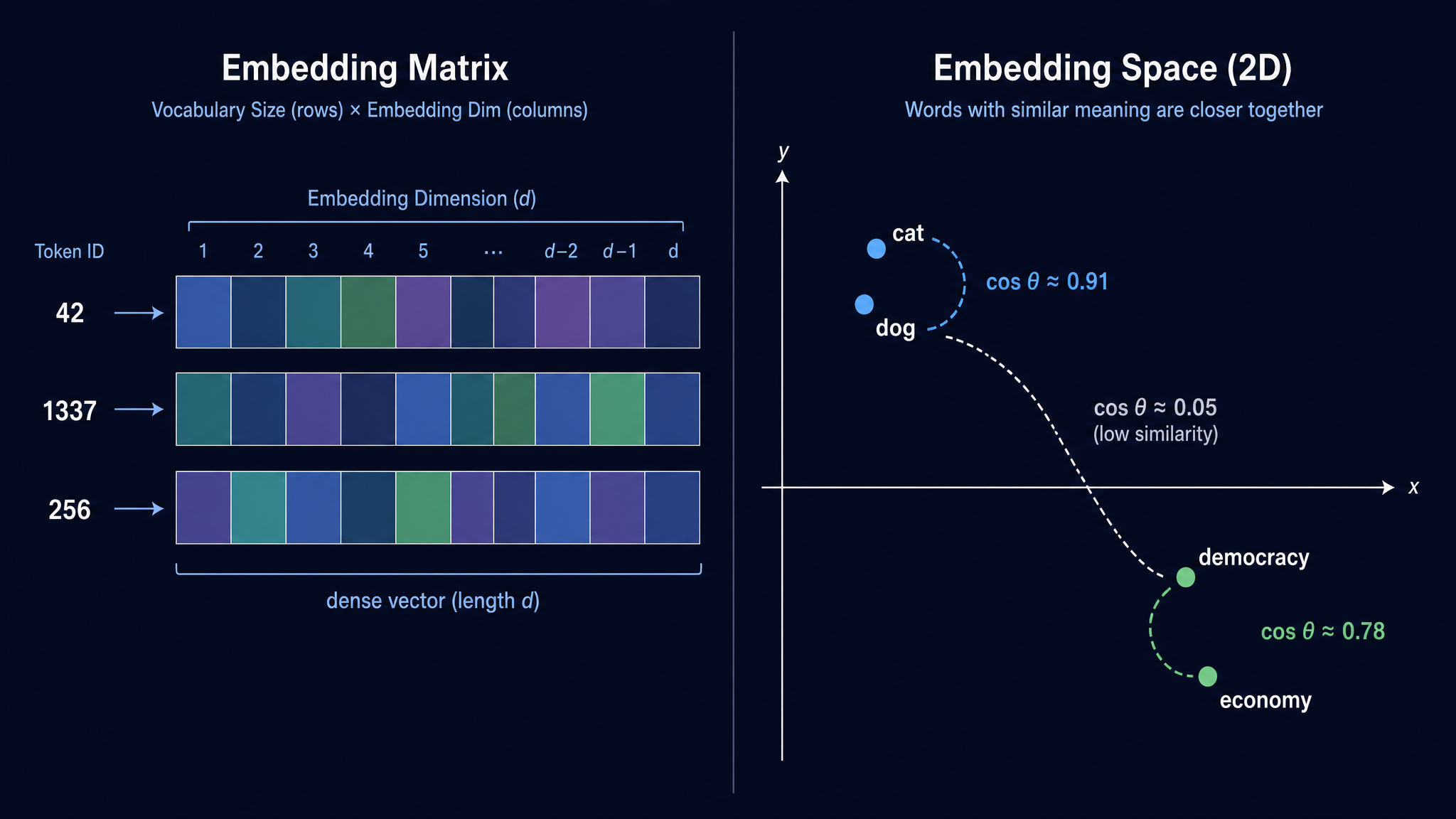
从 one-hot 到稠密向量
最朴素的表示方式是 one-hot:token ID=42 对应一个 32000 维的向量,只有第 42 位是 1,其余全是 0。
这种表示有一个根本问题:任意两个 one-hot 向量的内积都是 0。“cat” 和 “dog” 之间的相似度 = “cat” 和 “democracy” 之间的相似度 = 0。模型无法从 one-hot 中获得任何语义信息。
Embedding 的做法: 用一个查找表把离散 ID 映射到低维稠密向量。
其中
1 | import torch |
这个查找表是模型的第一个可学习参数。训练过程中,embedding 向量会逐渐学到语义关系——“cat” 和 “dog” 的向量会逐渐靠近,而与 “democracy” 拉远。这个矩阵定义了模型的语义空间:在这个空间里,距离代表语义相似度。
位置编码:让模型知道顺序
Embedding 解决了语义表示的问题,但还有一个问题:Self-Attention 是排列不变的(permutation invariant)。“猫追狗” 和 “狗追猫” 如果只看 token 集合不看顺序,模型得到的表示完全相同。
需要在 embedding 上叠加位置信息。
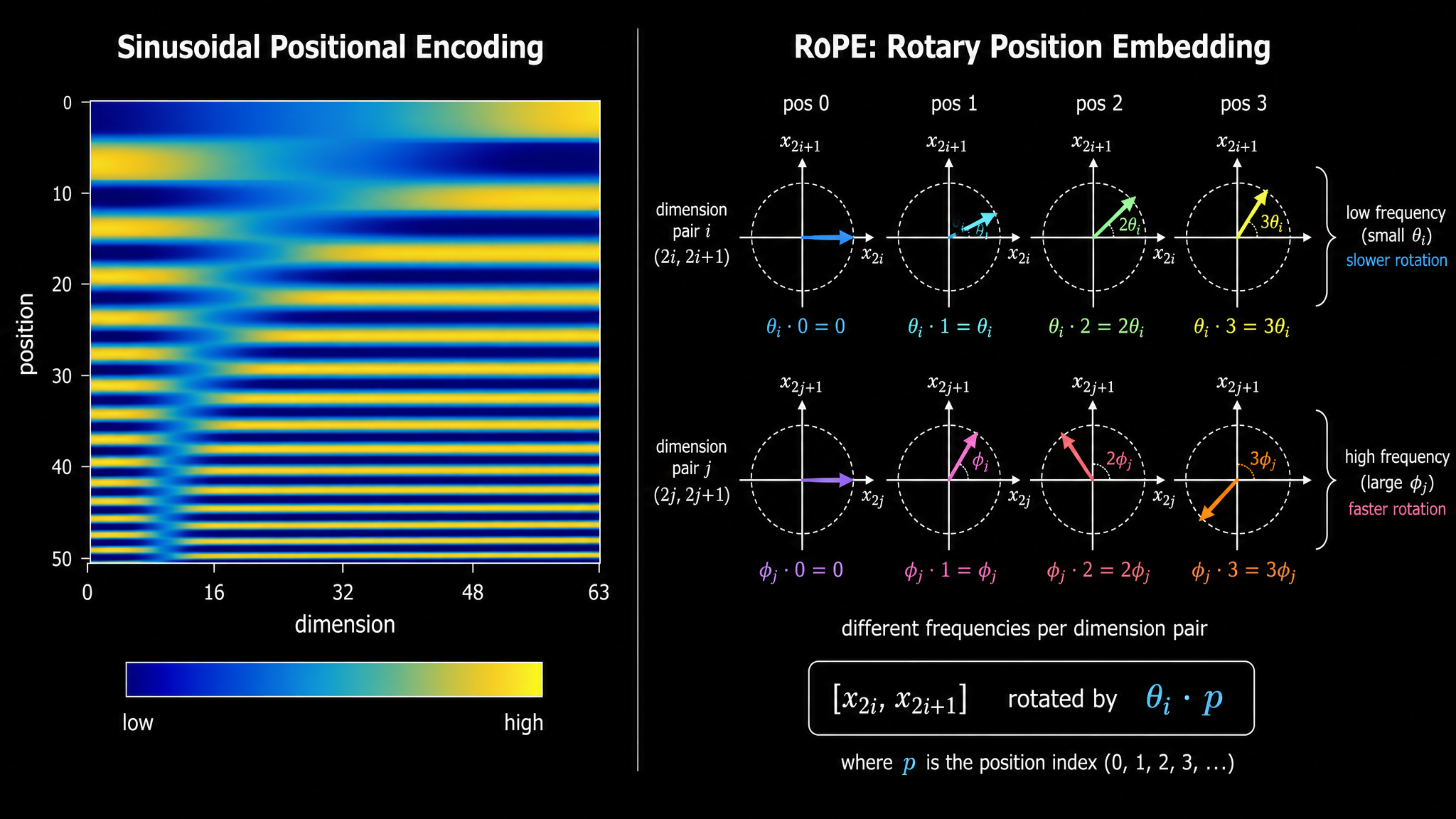
正弦位置编码(原始 Transformer):
不同维度用不同频率的正弦/余弦函数。任意两个位置的相对距离可以用线性变换表示,不需要学习,可以泛化到训练时未见过的长度。
RoPE(旋转位置编码):
现代 LLM(Llama、DeepSeek、Qwen)普遍使用 RoPE。RoPE 通过旋转 query 和 key 向量来编码位置。
对于位置
具体做法是将
Embedding 层的工程参数
Llama 2 7B 的 Embedding 矩阵
初始化通常使用
到这里,我们完成了从原始文本到连续向量的全部变换:
graph LR
A["原始语料"] -->|"去重 + 质量过滤"| B["清洗文本"]
B -->|"BPE Tokenization"| C["Token IDs"]
C -->|"Embedding + RoPE"| D["向量序列 ∈ ℝᴺˣᵈ"]
D -->|"送入 Transformer"| E["???"]
style A fill:#fff8e1,stroke:#ff9800,color:#333
style B fill:#f0f4ff,stroke:#5b8def,color:#333
style C fill:#f0f4ff,stroke:#5b8def,color:#333
style D fill:#e8f5e9,stroke:#4caf50,color:#333
style E fill:#fce4ec,stroke:#ef5350,color:#333
每个 token 现在是一个
→ 第二篇:Transformer 的 Self-Attention 机制让每个 token 能"看到"整个序列的上下文。