LLM 的训练与对齐
你做了一个客服机器人。用户问:“我的订单什么时候到?”
预训练模型的回答是:“我的订单什么时候到?这是一个常见的问题。订单的到达时间取决于多个因素,包括发货地、目的地、物流公司…”
用户要的是一个具体的日期,不是一篇物流科普文章。
这是每个做 LLM 应用的人都会遇到的问题:预训练模型会写文章,但不会回答问题。
你可能觉得这是 prompt 的问题,试了各种 prompt engineering 技巧,发现效果有限。根本原因不在 prompt,而在模型本身——它没有学过"什么是好的回答"。
本篇讲的就是如何让模型从"会写"变成"会答"。
一、预训练模型为什么不会回答问题
预训练的目标是预测下一个 token。这个目标让模型学会了语言的统计规律,但没有教它什么是"好的回答"。
你问它"我的订单什么时候到",它会续写"我的订单什么时候到?这是一个常见的问题…"——因为它在训练数据里见过最多的就是这种"百科全书式"的写法。
问题出在损失函数:
这个函数只关心"预测准不准",不关心"回答好不好"。模型学会了语言的模式,但不知道人类想要什么样的回答。
核心洞察: 预训练让模型学会了"怎么说",但没有教它"说什么"。这是两个完全不同的能力。
graph LR
A["预训练目标<br/>预测下一个 token"] -->|结果| B["语言模式<br/>(会续写)"]
B -->|问题| C["不会回答问题<br/>只会百科全书式续写"]
C -->|解决| D["对齐<br/>教模型什么是好回答"]
style A fill:#fff8e1,stroke:#ff9800,color:#333
style B fill:#f0f4ff,stroke:#5b8def,color:#333
style C fill:#fce4ec,stroke:#ef5350,color:#333
style D fill:#e8f5e9,stroke:#4caf50,color:#333
二、SFT:教模型模仿人类
最直接的解决方案是:给模型看一批人类写好的回答,让它学会模仿。
这就是 SFT(Supervised Fine-Tuning)。你收集一批 (instruction, response) 对,用监督学习微调模型。
1 | # SFT 数据:客服场景 |
SFT 的损失函数和预训练一样是交叉熵,但只在 response 部分计算:
1 | def sft_loss(model, instruction, response): |
为什么 instruction 部分的 loss 要忽略?因为 instruction 是输入,不是模型要学习的输出。模型只需要学会"看到这个 instruction 后,生成这个 response"。
认知反转: SFT 的效果取决于数据质量,不是数量。LIMA 论文用 1000 条高质量数据就达到了不错的效果。这说明模型在预训练阶段已经学到了足够的知识,SFT 只是教它"怎么说"。
但 SFT 有个根本问题:它只能模仿,不能选择。
graph LR
A["预训练模型<br/>(会续写)"] -->|SFT| B["SFT 模型<br/>(会回答)"]
B -->|问题| C["不知道哪个回答更好"]
C -->|解决| D["需要人类偏好"]
style A fill:#fff8e1,stroke:#ff9800,color:#333
style B fill:#f0f4ff,stroke:#5b8def,color:#333
style C fill:#fce4ec,stroke:#ef5350,color:#333
style D fill:#e8f5e9,stroke:#4caf50,color:#333
三、RLHF:让人类告诉模型哪个更好
SFT 只教了模仿,没有教选择。同一个问题可能有多个回答,哪个更好?
1 | prompt = "我的订单什么时候到?" |
RLHF(Reinforcement Learning from Human Feedback)的核心思想是:让人类告诉模型"哪个回答更好",然后用强化学习优化模型。
三步流程:
第一步:收集偏好数据
对同一个 prompt,让模型生成多个回答,人工排序。
1 | prompt = "我的订单什么时候到?" |
第二步:训练 Reward Model
用偏好数据训练一个打分模型
1 | class RewardModel(nn.Module): |
第三步:PPO 优化策略
用 Reward Model 的打分来优化语言模型。但不能直接最大化 reward——那样模型可能会生成"讨好" Reward Model 的回答,而不是真正好的回答。所以要用 KL 散度约束,让模型不要偏离 SFT 模型太远。
这个公式里:
:Reward Model 的打分,告诉模型"这个回答有多好" :KL 散度惩罚,防止模型偏离 SFT 模型太远
如果删掉 KL 项会怎样?模型会生成"讨好" Reward Model 的回答——可能语法正确、逻辑通顺,但不是人类真正想要的。这就是所谓的"reward hacking"。
graph TD
A["同一 prompt"] -->|生成| B["多个回答"]
B -->|人工排序| C["偏好数据"]
C -->|训练| D["Reward Model"]
D -->|打分| E["PPO 优化"]
E -->|更新| F["对齐模型"]
style A fill:#fff8e1,stroke:#ff9800,color:#333
style B fill:#f0f4ff,stroke:#5b8def,color:#333
style C fill:#f0f4ff,stroke:#5b8def,color:#333
style D fill:#f0f4ff,stroke:#5b8def,color:#333
style E fill:#fce4ec,stroke:#ef5350,color:#333
style F fill:#e8f5e9,stroke:#4caf50,color:#333
RLHF 的问题: 需要维护 4 个模型(Policy, Reference, Reward, Value),显存开销大,工程复杂。训练时需要同时跑 4 个模型的前向传播,对硬件要求很高。
ChatGPT 就是用 RLHF 训练的。但 OpenAI 有大量 GPU 资源,普通团队很难复现。有没有更简洁的方案?
四、DPO:去掉 Reward Model
RLHF 的复杂性主要来自 Reward Model 的训练和 PPO 的优化。DPO(Direct Preference Optimization)的核心 insight 是:可以绕过 Reward Model,直接从偏好数据优化策略。
这个 insight 来自一个数学推导:RLHF 的最优解可以重写为一个简单的分类损失。
DPO 的损失函数:
其中
这个公式里:
:策略模型相对于参考模型对偏好回答的"偏好程度" :策略模型相对于参考模型对被拒绝回答的"偏好程度" - 两者相减:让模型更倾向于生成偏好回答,远离被拒绝回答
如果删掉参考模型的 log 概率会怎样?模型会直接最大化偏好回答的概率,忽略与参考模型的差异。这会导致模型生成"奇怪"的回答——虽然概率高,但不是人类想要的。
核心洞察: DPO 的本质是让模型学习"相对偏好",而不是"绝对好坏"。这比 RLHF 更稳定,因为相对偏好比绝对打分更容易标注。
graph LR
A["RLHF<br/>4 个模型"] -->|简化| B["DPO<br/>2 个模型"]
B -->|去掉| C["Reward Model"]
C -->|结果| D["训练更简单"]
style A fill:#fff8e1,stroke:#ff9800,color:#333
style B fill:#f0f4ff,stroke:#5b8def,color:#333
style C fill:#fce4ec,stroke:#ef5350,color:#333
style D fill:#e8f5e9,stroke:#4caf50,color:#333
DPO 是离线方法,只能从已有的偏好数据学习。有没有在线方法,让模型在训练过程中自己探索?
五、GRPO:让模型自己探索
DPO 的局限是它只能从已有的偏好数据学习。DeepSeek-R1 提出了 GRPO(Group Relative Policy Optimization),让模型在训练过程中自己生成回答,然后组内比较。
核心思想: 对每个 prompt 采样 G 个回答,用组内相对排名估计优势:
这个公式的含义是:一个回答的好坏不是绝对的,而是相对于同组其他回答的。如果一个回答比组内平均好,它的 advantage 就是正的;反之就是负的。
认知反转: GRPO 去掉了 Critic(Value Model),用组内相对比较代替绝对打分。这让训练更简单,显存需求更低。DeepSeek-R1 用 GRPO 训练出了强大的推理能力,证明了这种方法的有效性。
graph TD
A["同一 prompt"] -->|采样| B["G 个回答"]
B -->|打分| C["G 个奖励"]
C -->|组内归一化| D["相对优势"]
D -->|优化| E["策略更新"]
style A fill:#fff8e1,stroke:#ff9800,color:#333
style B fill:#f0f4ff,stroke:#5b8def,color:#333
style C fill:#f0f4ff,stroke:#5b8def,color:#333
style D fill:#fce4ec,stroke:#ef5350,color:#333
style E fill:#e8f5e9,stroke:#4caf50,color:#333
六、DAPO:工业级改进
GRPO 在工业实践中遇到了新问题:某些 prompt 的所有回答都对或都错,无法提供有效梯度。
举个例子:假设一个简单的数学题 “1+1=?”,模型生成的 8 个回答全是 “2”。所有回答的奖励都一样,advantage 全是 0,梯度为 0,模型无法从这个 prompt 学到任何东西。
DAPO(Dynamic Sampling Policy Optimization)解决了这个问题。
四个关键技术:
Clip-Higher: 放宽正 Advantage 的 clipping 上界,鼓励探索。PPO 的 clipping 会限制策略更新幅度,但 DAPO 发现对正 Advantage 放宽限制可以让模型更积极地探索好的回答。
Dynamic Sampling: 过滤全对/全错的 prompt。如果一个 prompt 的所有回答都对或都错,说明这个 prompt 对当前模型没有学习价值,直接跳过。
Overlong Filtering: 超长回答 reward 设为 0(非负奖励),避免惩罚短回答。有些模型会生成很长的回答来"凑"奖励,DAPO 通过设置长度上限来避免这个问题。
Token-level Loss: 按 token 计算损失,避免长序列被过度加权。传统方法按 sequence 计算 loss,长序列的梯度会更大。DAPO 改为按 token 计算,让每个 token 的贡献相等。
graph LR
A["GRPO 问题"] -->|全对/全错| B["无有效梯度"]
B -->|解决| C["Dynamic Sampling"]
C -->|过滤| D["有效训练样本"]
style A fill:#fff8e1,stroke:#ff9800,color:#333
style B fill:#fce4ec,stroke:#ef5350,color:#333
style C fill:#f0f4ff,stroke:#5b8def,color:#333
style D fill:#e8f5e9,stroke:#4caf50,color:#333
七、RLVR:可验证领域的对齐
前面的对齐方法都需要人类标注或学习得到的奖励模型。在数学、代码等可验证领域,可以用基于规则的确定性验证器提供奖励。
数学验证:
1 | def math_verifier(question, response): |
代码验证:
1 | def code_verifier(question, response): |
RLVR 的好处是:不需要人类标注,奖励信号完全自动化。这使得训练可以大规模扩展,不需要昂贵的人工标注。
DeepSeek-R1 使用 RLVR + GRPO 训练,模型自发涌现出自我反思、多路径探索等推理行为。这说明 RLVR 不仅能提升准确性,还能激发模型的推理能力。
DeepSeek-R1 的完整流程:
- SFT 冷启动: 用含思维链的指令数据微调,学会格式与基础推理
- RL 推理训练 (RLVR): 在数学、代码等可验证领域用 GRPO/DAPO 训练
- 偏好对齐: 用 DPO 或 RLHF 进行最终对齐
- 蒸馏(可选): 用大模型生成推理数据,蒸馏至小模型
回到开篇的问题:“我的订单什么时候到?”
预训练模型会续写,SFT 模型会回答,RLHF/DPO 模型会选择好的回答,GRPO/DAPO 模型会优化回答,RLVR 模型会推理后回答。
对齐方法的演进遵循同一模式:从模仿到选择,从离线到在线,从人工标注到自动验证。
graph LR
A["预训练模型<br/>(会续写)"] -->|SFT| B["指令遵循模型<br/>(会回答)"]
B -->|RLHF/DPO| C["对齐模型<br/>(会选择)"]
C -->|GRPO/DAPO| D["探索模型<br/>(会优化)"]
D -->|RLVR| E["推理模型<br/>(会思考)"]
style A fill:#fff8e1,stroke:#ff9800,color:#333
style B fill:#f0f4ff,stroke:#5b8def,color:#333
style C fill:#f0f4ff,stroke:#5b8def,color:#333
style D fill:#e8f5e9,stroke:#4caf50,color:#333
style E fill:#fce4ec,stroke:#ef5350,color:#333
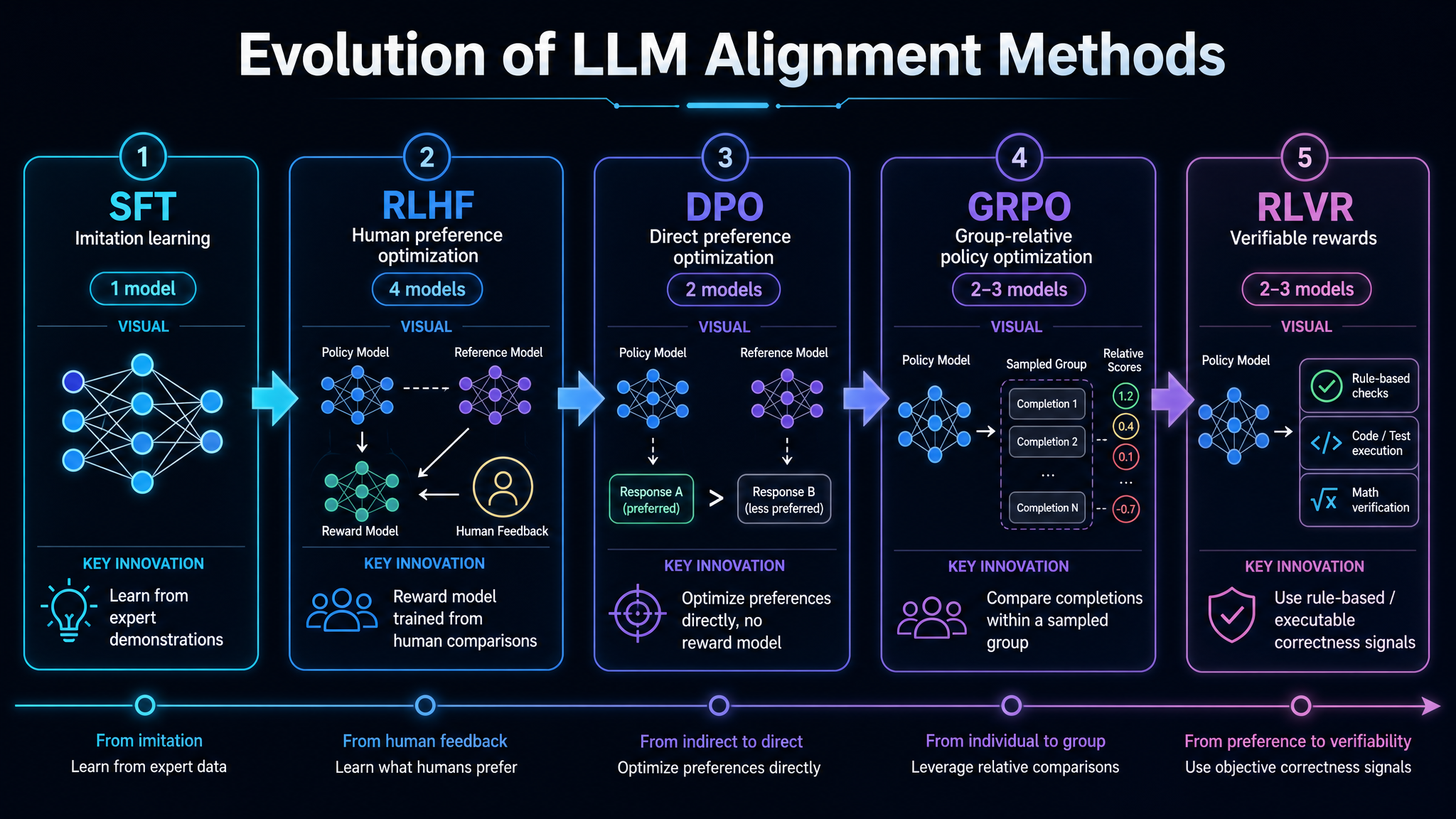
每一步改进都在解决前一步的问题:SFT 解决了"会回答",RLHF 解决了"会选择",DPO 去掉了 Reward Model,GRPO 去掉了 Critic,DAPO 解决了工业实践问题,RLVR 解决了标注成本问题。