ConcurrentHashMap是如何解决并发问题的?
ConcurrentHashMap是如何解决并发问题的?
ConcurrentHashMap
JDK 1.7
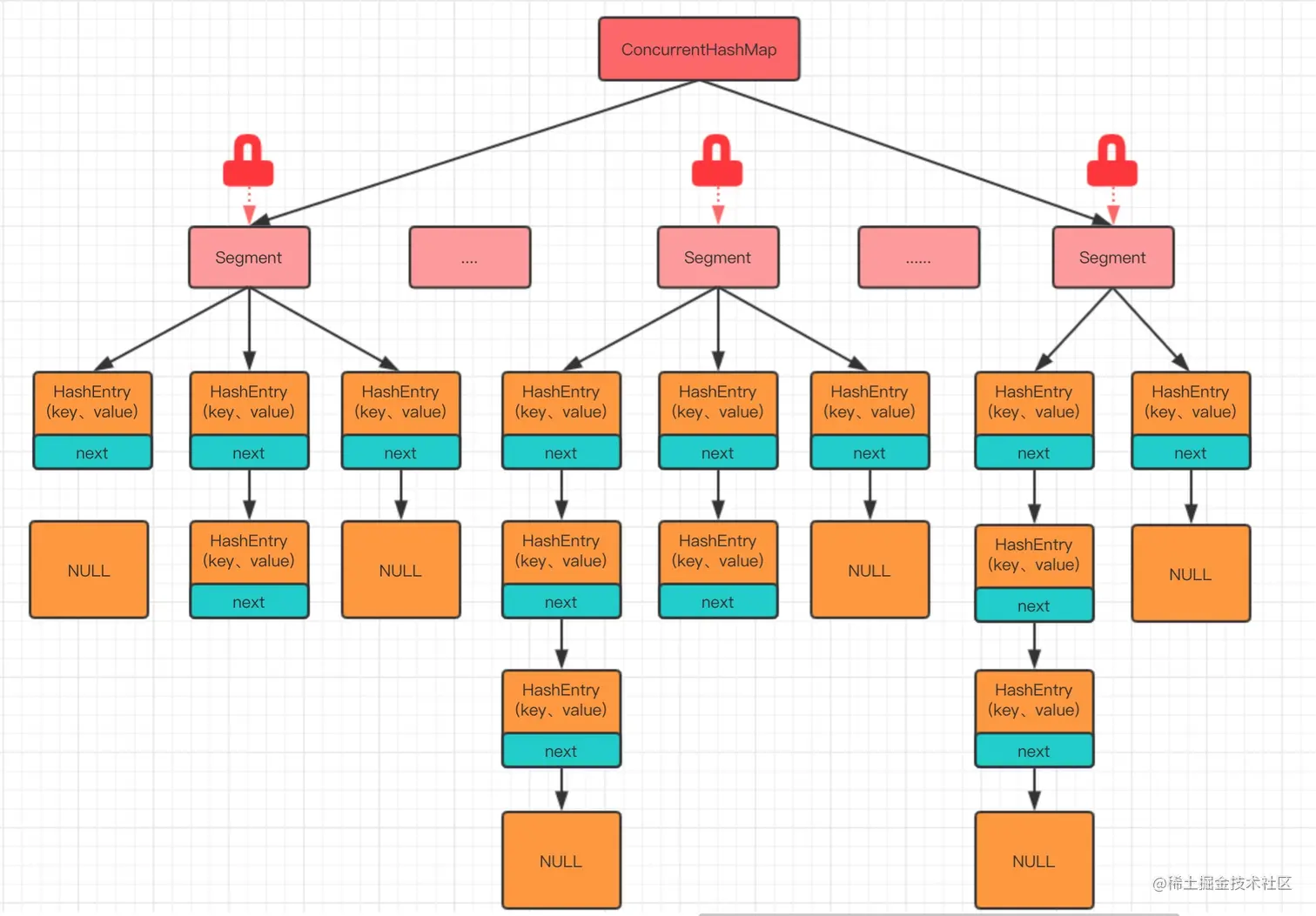
在JDK 1.7中,ConcurrenctHashMap采用了分段锁的机制,把整个HashMap分成了多个Segment,当某个桶需要加锁时,只会锁住对应的Segment,而不是整个Map。如图:
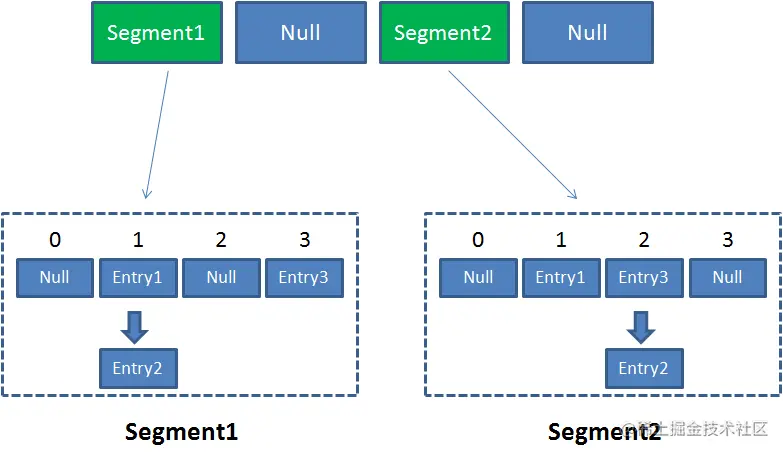
同时,在单个Segment的内部,也存有若干Entry(即内部有一个Entry数组):
基于以上特殊结构,不难发现:
| 操作 | 是否能并发执行 |
|---|---|
| 对不同Segment进行写操作 | 是 |
| 对同一Segment进行读写操作 | 是 |
| 对同一Segment进行写操作 | 否 |
get方法
伪代码如下:
// ConcurrentHashMap 类的 get 方法
V get(Object key) {
// 1. 如果 key 为 null,抛出 NullPointerException
if (key == null) {
throw new NullPointerException();
}
// 2. 计算 key 的哈希值,并将其扩展,以减少哈希冲突。
int h = hash(key);
// 3. 根据哈希值定位到具体的 Segment。
// Segment 是一个独立的锁,整个 get 过程都不需要获取它。
Segment s = segments[h % segments.length];
// 4. 在定位到的 Segment 中,根据哈希值找到对应的 HashEntry 数组索引。
// 这一步也是无锁的。
HashEntry[] tab = s.table;
int index = (tab.length - 1) & h;
// 5. 遍历该索引处的链表(或红黑树,但在 JDK 1.7 中是链表)
// 这个遍历也是无锁的。
for (HashEntry<K,V> e = tab[index]; e != null; e = e.next) {
// 6. 检查当前 HashEntry 是否是我们要找的键值对。
// 使用哈希值和 equals 方法进行双重检查。
if (e.hash == h && key.equals(e.key)) {
// 7. 核心:返回 HashEntry 的 value 字段。
// 因为 value 字段是用 volatile 修饰的,这保证了内存可见性。
// 当其他线程通过 put 或 remove 修改了 value 后,这个线程能立即看到最新值。
return e.value;
}
}
// 8. 如果遍历完整个链表都没有找到,则返回 null。
return null;
}
- 整个方法都没有使用
synchronized或ReentrantLock来加锁。这也是ConcurrentHashMap读取效率高的原因。 HashEntry中的value字段被声明为volatile。这保证了当一个线程更新了值后,这个更新对所有其他线程都是立即可见的,从而避免了脏读。
put方法
伪代码如下:
// ConcurrentHashMap 类的 put 方法
V put(K key, V value) {
// 1. 如果 key 或 value 为 null,抛出异常。
if (key == null || value == null) {
throw new NullPointerException();
}
// 2. 计算 key 的哈希值。
int h = hash(key);
// 3. 根据哈希值定位到具体的 Segment。
// 这也是分段锁的核心。
Segment<K,V> s = segments[h % segments.length];
// 4. 获取 Segment 锁。
// 这一步是 put 方法与 get 方法最大的不同,它确保了数据修改的线程安全。
s.lock();
try {
// 5. 在 Segment 内部执行操作。
// 获取 HashEntry 数组。
HashEntry<K,V>[] tab = s.table;
// 6. 根据哈希值找到 HashEntry 数组中的索引。
int index = (tab.length - 1) & h;
// 7. 遍历链表,查找是否已存在相同的键。
// 如果找到,则更新 value 并返回旧值。
for (HashEntry<K,V> e = tab[index]; e != null; e = e.next) {
if (e.hash == h && key.equals(e.key)) {
// 旧值被 volatile 修饰,确保可见性。
V oldVal = e.value;
e.value = value;
return oldVal;
}
}
// 8. 如果没有找到,则创建新的 HashEntry 并插入到链表头部。
// 首先,记录旧的链表头。
HashEntry<K,V> oldHead = tab[index];
// 创建新的 HashEntry,并将其 next 指向旧的链表头。
HashEntry<K,V> newEntry = new HashEntry<>(h, key, value, oldHead);
// 更新数组中对应索引处的引用,使新 entry 成为链表头。
tab[index] = newEntry;
// 9. 增加 Segment 的 size。
s.count++;
// 10. 检查是否需要对 Segment 进行扩容。
// 如果 size 超过了阈值,则触发扩容操作。
// 这部分逻辑较为复杂,通常涉及重新哈希和重建数组。
if (s.count > s.threshold) {
s.rehash();
}
// 11. 如果是新插入的元素,返回 null。
return null;
} finally {
// 12. 释放 Segment 锁。
// 这一步至关重要,必须确保锁在任何情况下都能被释放。
s.unlock();
}
}
// 内部类 HashEntry
// value 字段被 volatile 修饰,保证了内存可见性。
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value; // 关键点:volatile 修饰
volatile HashEntry<K,V> next;
// ... 构造函数等
}
- 原本HashMap的put操作是无法保证原子性的,所以使用
s.lock()加锁,阻止其它线程访问。 - 与HashMap不同,ConcurrentHashMap是插入之前判断是否需要扩容,而HashMap是插入之后才判断是否需要扩容。
JDK 1.8
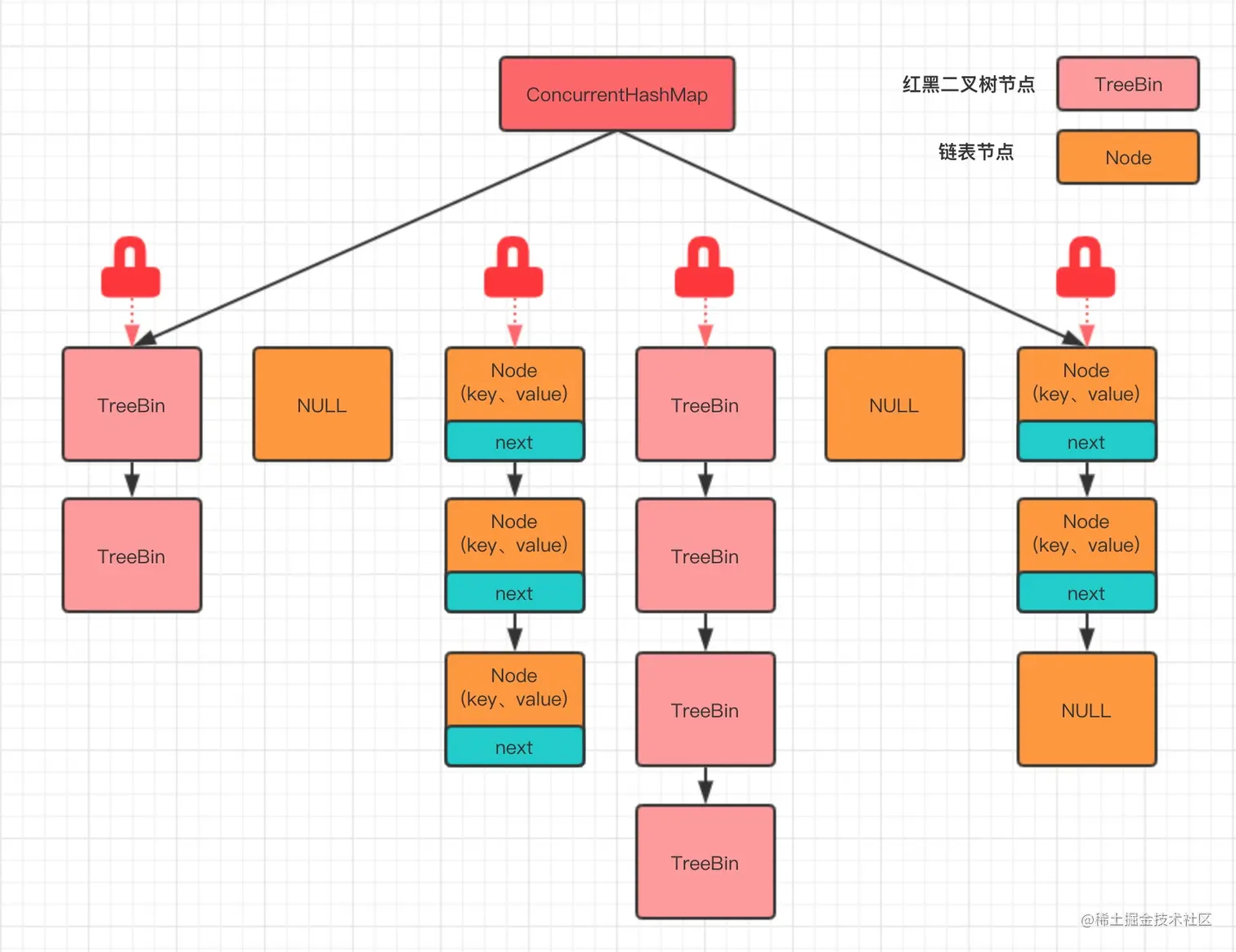
JDK 1.8中,ConcurrentHashMap又进行了优化:
- 与HashMap相同,采用树化机制防止链表过长
- 摒弃1.7的分段锁机制,转向以链表头节点/树根节点 加锁,配合CAS + synchronized ,提高并发性能
结构如图:
put方法
源码截图如下:
其实主要分为三个机制:
- 桶为空桶时,采用
CAS机制插入数据 - 桶不为空,则用
synchronized锁住头节点 - 需要扩容时,通过
MOVED+helpTransfer确保并发安全
get方法
- 跟HashMap一样,添加树化机制优化查询效率
补充
CAS机制
CAS(Compare-And-Swap) ,是一种乐观锁机制,是无锁并发编程的核心。伪代码如下:
boolean CAS(address, expected, newValue) {
if (*address == expected) {
*address = newValue;
return true;
}
return false;
}
总体流程可以简化为:
- 判断地址的旧值是否等于期望旧值
- 如果相等,就认为它没有被其它线程操作,更新旧值为新值
- 如果不相等,说明它已经被别的线程操作,失败或重试
在 Java 里,CAS 主要依赖 Unsafe 类 或 VarHandle 来操作内存。
CAS的缺点 :
- ABA 问题 :变量值从 A → B → A,CAS 认为没变,但其实中间变过。
- 解决方案:版本号 + 值 ,即 AtomicStampedReference
- 自旋开销大 :多次 CAS 失败会一直自旋,浪费 CPU
ConcurrentHashMap扩容是如何保证并发安全的?
ConcurrentHashMap 是通过 MOVED 标记 + CAS + 分桶锁 来保证安全的。
- MOVED标记 :
当桶的头节点迁移成功时,其hash字段会标记为常量MOVED,此时其它线程会迁移下一个桶 - CAS :
if (casTabAt(oldTable, i, f, MOVED_NODE)) {
// 只有成功的线程才迁移这个桶
moveBucket(f, newTable);
}
CAS操作成功时,说明该线程负责本桶的操作;
如果失败,说明其它线程正在迁移,当前线程就会等待或者迁移下一个桶 - 分桶锁
迁移桶内部的链表或树节点时,如果涉及到修改节点指针,ConcurrentHashMap 会 只锁当前桶头节点 - helpTransfer方法
- 新建扩容后的table
- 每个线程维护一个 迁移索引(transferIndex) ,表示还未迁移的桶范围
- 线程抢到一个桶范围后:
- 遍历该桶的节点
- 重新计算新桶位置
- 插入新表
- 用 CAS 把旧桶标记为
MOVED
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Aromatic!
相关推荐

2025-09-26
ArrayList和Vector底层初探
ArrayList和Vector底层初探 ArrayList ArrayList 实现于 List、RandomAccess 接口。可以插入空数据,也支持随机访问。 ArrayList有两个重要属性: Object[] : elementData int : size add方法 默认add(E e) : public boolean add(E e) { // 1. 确保容量足够 ensureCapacityInternal(size + 1); // 2. 将元素添加到数组末尾 elementData[size++] = e; return true; } 确保容量足够 -> 将元素添加到数组末尾 -> 尺寸递增 指定下标add(int index, E e) : public void add(int index, E element) { rangeCheckForAdd(index); ensureCapacityInternal(size + 1); // Increments modCount!! //复制,向后移动 ...

2025-09-30
HashSet底层初探
HashSet底层初探 HashSet是Java集合框架中一个重要的实现类,它基于HashMap实现,具有不允许重复元素 、允许null值 、无序存储 等特性。作为最常用的Set实现,HashSet在去重、快速查找等场景中发挥着重要作用。 核心数据结构 HashSet的内部实现采用了适配器模式 ,通过组合HashMap来实现Set接口的功能。 private transient HashMap<E,Object> map; // Dummy value to associate with an Object in the backing Map private static final Object PRESENT = new Object(); 关键设计要点 : map属性 :HashSet内部维护一个HashMap实例,所有Set操作都委托给这个HashMap处理 PRESENT常量 :作为HashMap的value值,由于Set只需要存储key,所以使用一个固定的Object对象作为占位符 transient关键字 :map字段被标记为transient,...

2025-09-27
LinkedList底层分析
LinkedList底层分析 LinkedList是Java集合框架中基于双向链表 实现的List接口,它同时实现了List和Deque接口,既可以作为列表使用,也可以作为双端队列使用。与ArrayList的数组实现不同,LinkedList通过节点间的指针连接实现动态存储。 一、底层数据结构 双向链表结构 从JDK 1.7开始,LinkedList采用双向链表 实现(早期版本使用循环链表),每个节点都包含指向前驱和后继节点的引用。 Node节点定义 private static class Node<E> { E item; // 存储的数据元素 Node<E> next; // 指向下一个节点的引用 Node<E> prev; // 指向上一个节点的引用 Node(Node<E> prev, E element, Node<E> next) { this.item = element; this...
2025-09-28
HashMap原理初探
HashMap原理初探 HashMap HashMap的底层是由数组+链表组成的,但JDK1.7和1.8的实现方式有所不同: JDK 1.7 JDK 1.7的HashMap数据结构如下: JDK 1.7的源码如下(图片源自HashMap? ConcurrentHashMap? 相信看完这篇没人能难住你! - crossoverJie’s Blog): 下面逐个解释每个属性的含义: 初始化桶的大小为16(不过官方推荐开发者在创建HashMap时手动指定容量) 桶容量的最大值为2^30 默认负载因子为0.75(影响扩容机制) Entry数组,用于存放数据 Map中元素的数量 桶大小,在HashMap初始化时显示指定 负载因子,在HashMap初始化时显示指定 那么Entry的底层结构又是什么呢? 不难看出,Entry的属性含义: key:写入的真实的键 value:写入的值 next:单向链表指向的下一个对象 hash:哈希值 了解了这些,我们再来看看方法实现: put方法 public V put(K key, V value) { if (tabl...
2025-09-29
图灵二面:手撕HashMap
图灵二面:手撕HashMap 面试官:既然你刚刚提到HashMap底层原理,想必你一定了解HashMap的结构。那你就手写一份自己的HashMap吧。 我:??? 先来看看我当时写的依托答辩: /** * @author Aromatic * @date 2025/6/18 下午3:21 * @description: */ public class MyHashMap { private int size; private List<List<Integer>>[] table; public void MyHashMap(){ this.size = 16; table = new List[size]; } public void MyHashMap(int size){ this.size = size; table = new List[size]; } pri...