HashMap原理初探
HashMap原理初探
HashMap
HashMap的底层是由数组+链表组成的,但JDK1.7和1.8的实现方式有所不同:
JDK 1.7
JDK 1.7的HashMap数据结构如下:
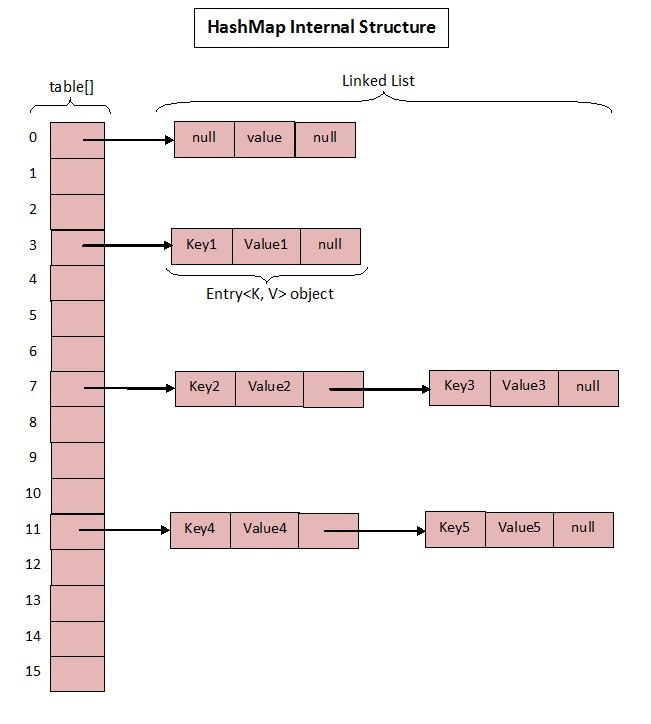
JDK 1.7的源码如下(图片源自HashMap? ConcurrentHashMap? 相信看完这篇没人能难住你! - crossoverJie’s Blog):
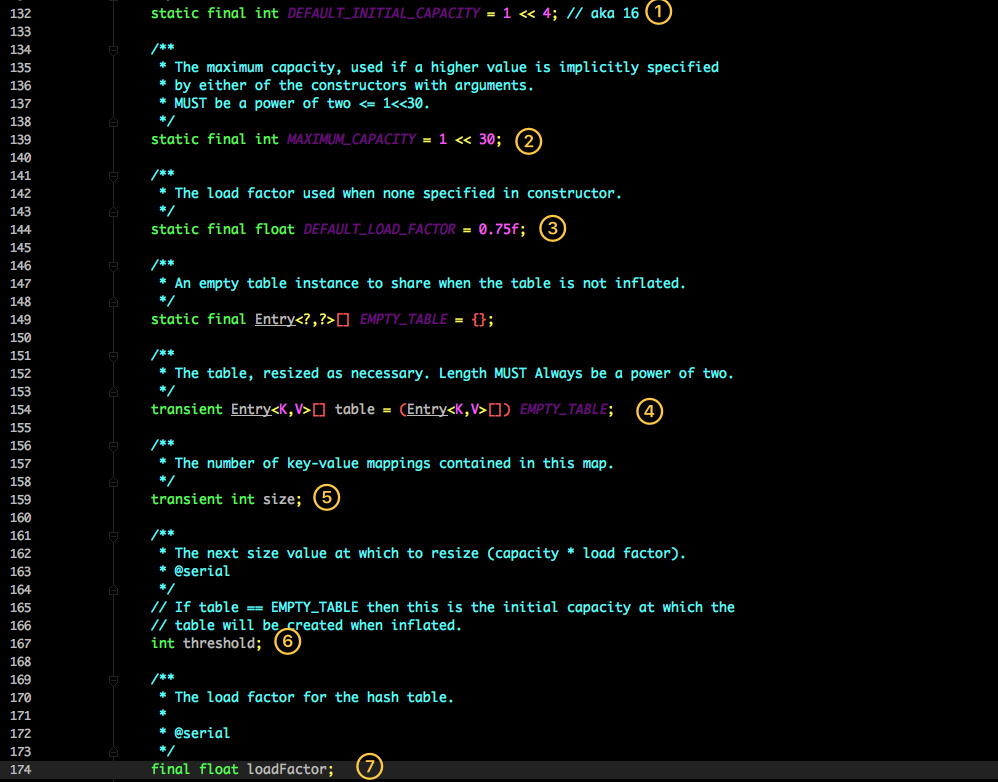
下面逐个解释每个属性的含义:
- 初始化桶的大小为16(不过官方推荐开发者在创建HashMap时手动指定容量)
- 桶容量的最大值为2^30
- 默认负载因子为0.75(影响扩容机制)
Entry数组,用于存放数据Map中元素的数量- 桶大小,在HashMap初始化时显示指定
- 负载因子,在HashMap初始化时显示指定
那么Entry的底层结构又是什么呢?
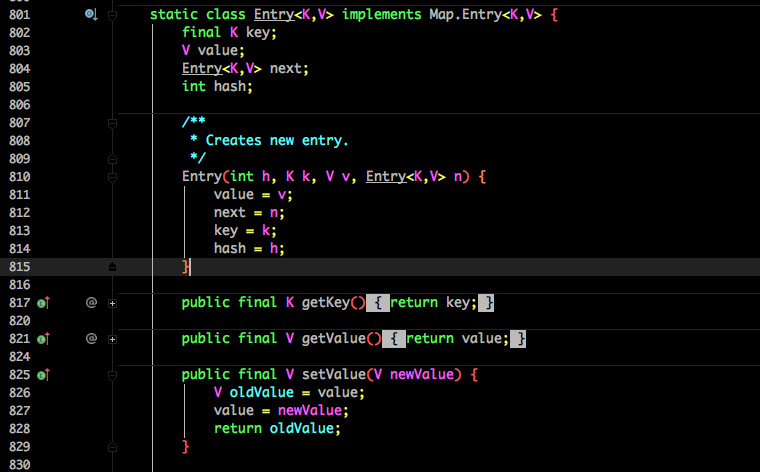
不难看出,Entry的属性含义:
- key:写入的真实的键
- value:写入的值
- next:单向链表指向的下一个对象
- hash:哈希值
了解了这些,我们再来看看方法实现:
put方法
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
主要逻辑如下:
- 如果是空桶,则初始化
- 如果key为空,则put空值
- 计算hash值,并定位index
- 逐个遍历桶上的链表的元素,如果key值相同(使用equals()方法比较),则覆盖value
- 如果没有匹配的key,则在末尾添加一个Entry
注意 :在调用addEntry方法时,会先判断是否需要扩容(如果需要则会两倍扩容)
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
get方法
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
主要流程如下:
- 如果key为空,返回空value
- 如果Map的大小为0,返回空value
- 逐个遍历桶上的链表,判断hash值和key值是否同时相等(在比较key值时,如果是基本数据类型则使用==判断,如果是引用则用.equals()方法判断)
- 找到,返回值;没找到,返回空
JDK 1.8
当出现严重的Hash冲突时(尤其是所有元素都在同一个桶上时,HashMap会退化成链表,严重影响查询效率),同一个桶上的链表会极大加长,影响查询效率。
JDK 1.8为了优化这种情况,在一定条件下,链表会转化成红黑树(复杂度从O(n)变成O(logn):
为此,HashMap中多了几个属性值:
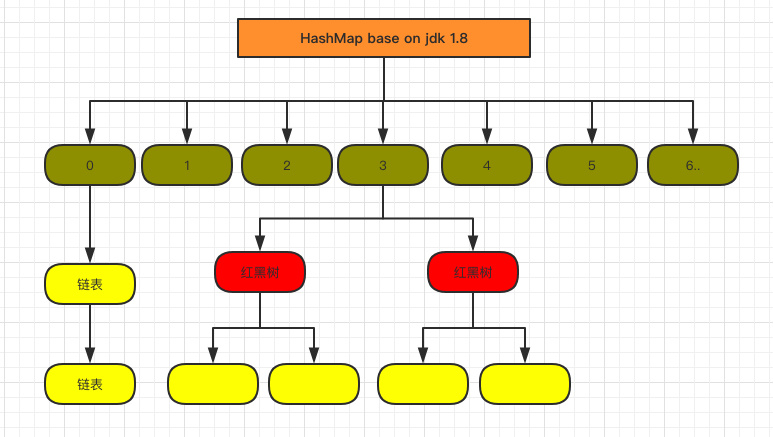

TREEIFY_THRESHOLD:链表转化成红黑树的阈值,即链表转化成红黑树所需要的节点数为8UNTREEIFY_THRESHOLD:红黑树退化成链表的阈值,默认为6MIN_TREEIFY_CAPACITY:进行树化操作的最小哈希容量为64
也就是说 ,只有当当前容量>=64,且桶上的链表节点>=8时,链表才会转化成红黑树;如果容量<64,则哈希表会扩容
遍历方式
-
使用迭代器对EntrySet进行遍历:
Iterator<Map.Entry<String, Integer>> entryIterator = map.entrySet().iterator();
while (entryIterator.hasNext()) {
Map.Entry<String, Integer> next = entryIterator.next();
System.out.println(“key=” + next.getKey() + " value=" + next.getValue());
} -
使用迭代器对KeySet遍历,再用key去查找value:
Iteratoriterator = map.keySet().iterator();
while (iterator.hasNext()){
String key = iterator.next();
System.out.println(“key=” + key + " value=" + map.get(key));} -
使用lambda表达式遍历(JDK >= 1.8):
map.forEach((key,value)->{
System.out.println(“key=” + key + " value=" + value);
});
显然 ,第一种比第二种的遍历效率快很多。
并发问题
环形链表问题
这是JDK 1.7时链表扩容采用头插法 导致的并发问题:

如图,导致环形链表的流程如下:
- 两个线程同时进行resize()方法
- 线程1得到调度,并成功将A迁移到目标位置,此时cur指向B,next指向C
- 线程2得到调度,完成了整个resize过程,此时头为C,且C的next指向B
- 线程1得到调度,cur指向的B再次进行头插发,把B的next指向C
- 此时,环形链表产生,会造成死循环
而JDK 1.8采用尾插法 ,避免了环形链表的产生(在刚才的情景中,指针会重复赋值两次,不会构造环)
数据丢失问题
这个是JDK所有版本的HashMap的并发问题,即当多个线程同时往一个桶里放数据时,后面的数据可能会覆盖前面的数据。